|
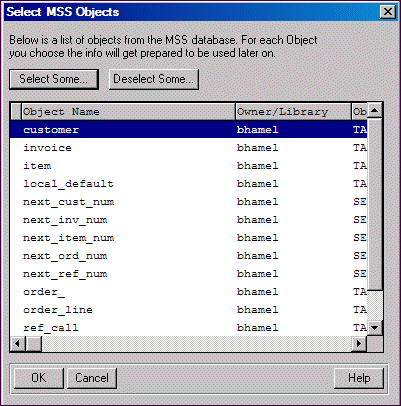
MS SQL Server Code page
|
OpenEdge equivalent
|
|
iso_1
|
iso8859-1 (default schema-holder code page)
|
|
cp850
|
ibm850
|
|
Interface element
|
Description
|
|
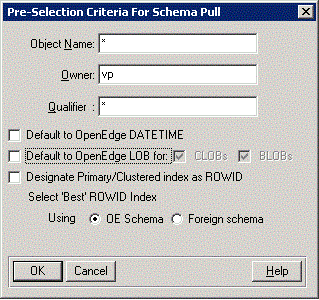
Object name
|
Specify an Object name qualifier for objects to be pulled for the server. The wild card default selects all objects. For example, you can specify A* in the Object Name field to list all the tables whose names begin with A or a.
Note: You should not specify an entry that consists exclusively of wild cards for each of the three entry fields in the dialog box. An entry that consists exclusively of wild cards might degrade the performance of the database when you perform a schema pull. (It will include system catalog files from the data source not typically included in user databases.)
|
|
Owner information
|
Specify an Object owner to be pulled for the server. The wild card default selects all objects. For example, you can specify DS* in the Owner information field to list all the tables whose names begin with A or a.
Note: You should not specify an entry that consists exclusively of wild cards for each of the three entry fields in the dialog box. An entry that consists exclusively of wild cards might degrade the performance of the database when you perform a schema pull. (It will include system catalog files from the data source not typically included in user databases.)
|
|
Qualifier
|
Specify an Object's qualifying database name to be pulled for the server. The wild card default selects all objects.
Note: You should not specify an entry that consists exclusively of wild cards for each of the three entry fields in the dialog box. An entry that consists exclusively of wild cards might degrade the performance of the database when you perform a schema pull. (It will include system catalog files from the data source not typically included in user databases.)
|
|
Default to OpenEdge DATETIME
|
Select Default to OpenEdge DATETIME to automatically map MS SQL Server timestamp data types to the associated OpenEdge equivalent DATETIME data type.
If this check box is not selected, server timestamp data types map to DATE data type in OpenEdge for backward compatibility.
|
|
Default to OpenEdge LOB for:
|
If you have modified your client application to handle LOB data types, select Default to OpenEdge LOB for: CLOBs and/or BLOBs to map the OpenEdge LOB data type to MS SQL Server VARBINARY(MAX), IMAGE and FILESTREAM data types.
If you do not select this option, all server LOB data types map to the CHARACTER data type in OpenEdge for backward-compatible.
For more information on mapping OpenEdge and MS SQL Server data types, see Support for OpenEdge ABL BLOB data type.
|
|
Designate Primary/Clustered index as ROWID
|
Specifying Designate Primary/Clustered index as ROWID for a table with a defined clustered index and without a defined PROGRESS_RECID field designates the clustered index as ROWID if it qualifies for ROWID selection.
For the clustered index to qualify for ROWID selection, it must be unique. This designation for ROWID takes precedence over any other options selected for the schema pull operation but does not overwrite a legacy ROWID designation that is based on the presence of PROGRESS_RECID.
Note: The Designate Primary/Clustered index as ROWID option may produce some or all of the "natural" key selections available from the foreign table's indexes. These can be considered alternatives to the PROGRESS_RECID column or other ROWIDs previously designated.
|
|
Select 'Best' ROWID Index
|
Selecting Select 'Best' ROWID Index during migration provides the legacy equivalent of ROWID designation behavior for the tables from prior versions of OpenEdge where the PROGRESS_RECID column was not present in a table.
When selected in conjunction with new process flow options for ROWID migration, this option plays a secondary role in the designation of ROWID indexes deferring to the Designate Primary/Clustered index as ROWID option as the first choice. This option searches for a viable index for ROWID when an PROGRESS_RECID column does not exist and other process flow options that take precedence do not render a viable index.
Select 'Best' ROWID Index using one of the following options:
When this option is used in conjunction with the Designate Primary/Clustered index as ROWID option, this option specifies a secondary path in the search for the ROWID index. The primary and clustered selections associated with those options will take priority in ROWID selection as does the presence of a PROGRESS_RECID column.
If this option is selected in conjunction with the Designate Primary/Clustered index as ROWID option, then a warning is generated with respect to both options. When both options are selected, this option becomes a secondary path in the search for the ROWID index. The primary and clustered selections associated with those options takes priority in ROWID selection as does the presence of a PROGRESS_RECID column.
|