This section addresses the steps needed to create a schema holder.
To create the schema holder:
1. From the Data Administration main menu, select DataServer > MS SQL Server Utilities > Create DataServer Schema.
The following dialog box appears:
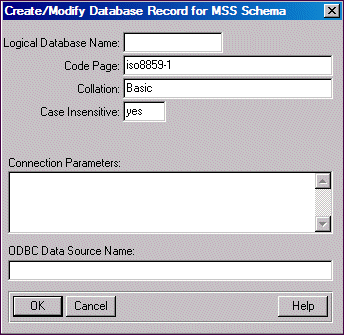
2. In the Logical Database Name field, type the name that you will use to connect to your data source and refer to it in your programming applications. This name must be different from the schema holder name. For more information on database names, see the database access chapter in OpenEdge Getting Started: ABL Essentials.
Note: If you place the schema from a second MS SQL Server database into a schema holder, the second schema must have a different logical database name from the first schema. The schema holder has one physical name, but each schema that it contains must have a different logical name.
3. In the Code Page field, type the name of the code page for the schema holder. The name must be the OpenEdge name for the code page that the data source uses. The default is iso8859-1. If you choose UTF-8 as your schema image code page, your schema holder's code page must also be UTF-8.
The following table lists the most common MS SQL Server database code pages and the equivalent OpenEdge names.
Table 32. MS SQL Server and OpenEdge code pages
MS SQL Server Code page
OpenEdge equivalent
iso_1
iso8859-1 (default schema-holder code page)
cp850
ibm850
If you use a code page that OpenEdge does not support, you must supply a conversion table that translates between the OpenEdge client code page and the code page that your data source uses. For a complete discussion of code pages, see OpenEdge Development: Internationalizing Applications.
4. In the Collation field, enter the name of the collation rule to use. The default is Basic. See Code pages for a discussion of collation issues to consider.
5. In the Case Insensitive field, the default value yes indicates that MS SQL Server's case insensitivity feature is in use. To change this value, type no.
6. Type the connection parameters in the Connection Parameters field.
See Connectingthe DataServer for a description of the required and optional connection parameters.
7. In the ODBC Data Source Name field, type the name that you used when you registered the data source with the ODBC administration tool.
8. Choose OK. The utility prompts you for your data source user ID and password. If they are required by the MS SQL Server data source and you did not provide the user ID and password in the Connection Parameters field (see Step 6), enter a valid data source user ID and password combination now. For more information, see Authorizationand Authentication.
9. Choose OK. When the DataServer connects to the MS SQL Server database, it reads information about data source objects.
The following dialog box appears:
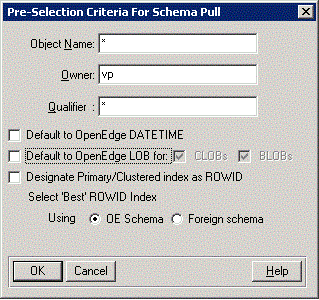
You can select tables based on the object name, owner/library information, and qualifier. For example, you can specify A* in the Object Name field to list all the tables whose names begin with A or a.
Note: Progress Software Corporation recommends that you do not specify an entry that consists exclusively of wild cards for each of the three entry fields in the dialog box. An entry that consists exclusively of wild cards might degrade the performance of the database when you perform a schema pull. (It will include system catalog files from the data source not typically included in user databases.)
Check Default to OpenEdgeDATETIME to automatically map MS SQL Server data types to the associated OpenEdge data type. If you have modified your client application to handle LOB data types, check Default to OpenEdge LOB for: CLOBs and/or BLOBs to map the OpenEdge LOB data type to MS SQL Server VARBINARY (MAX), IMAGE and FILESTREAM data types. For more information on mapping OpenEdge and MS SQL Server data types, see Support for OpenEdge ABL BLOB data type . If you select Designate Primary/Clustered index as ROWID, you will get the warning "Existing ROWID designations may be overwritten by selecting this option". If selected, and a given table has a clustered index and does not have the PROGRESS_RECID field defined for it, it will be used as ROWID if it qualifies for ROWID selection. Qualification requires that the index be unique. This designation for ROWID takes precedence over any other options selected for the schema pull operation but does not overwrite a ROWID designation that is based on the presence of PROGRESS_RECID. When the Select 'Best' ROWID Index is selected, this option provides a legacy option for selecting ROWID when the PROGRESS_RECID column is not present in the table. When selected in conjunction with new process flow options for ROWID migration, this option plays a secondary role in the designation of ROWID indexes deferring to the Designate Primary/Clustered index as ROWID option as the first choice. This option searches for a viable index for ROWID when an PROGRESS_RECID column does not exist and other process flow options do not render a viable index.
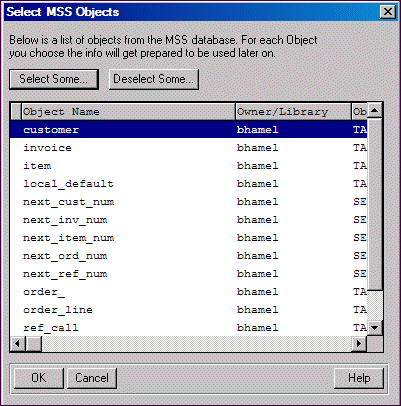
OpenEdge displays a list of the data source objects that you can include in the schema holder, as shown:
If you specified all wild cards as your table-selection criteria, the list might also include system-owned objects, which you do not have to include in the schema holder.
11. Click the option appropriate to the action you want to perform:
Select Some — Displays the Select by Pattern Match dialog box on which you can specify object information used to select objects.
Deselect Some — Displays the Deselect by Pattern Match dialog box on which you can specify object information used to deselect objects.
You can also elect to select and deselect individual objects by clicking and double-clicking on an object. An asterisk appears next to an object that has been selected; double-click an object to remove the asterisk and identify that the object is now deselected.
12. Choose OK after you have identified all the objects you want to include in the schema holder. The DataServer reads information about the objects that you select and loads their data definitions into the schema holder. The time that this process takes depends on the size and number of objects that you select.
For each table selected, the DataServer attempts to select an index to support the OpenEdge ROWID. If an appropriate index does not exist, the DataServer issues the warning, Please check errors, warnings and messages in the file ds_upd.e. The ds_upd.e file lists the objects that do not support ROWID. You can change the DataServer's selection of an index to support ROWID by using the Data Dictionary. See Defining theROWID for instructions. For additional information, see Indexes andsorting.