
|
pro source_db -p prodict/ora/protoora.p
|
|
Interface Element
|
Description
|
|
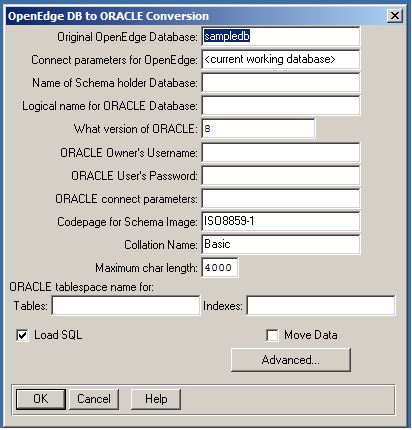
Original OpenEdge Database
|
The source database name. Accept the default value.
|
|
Connect parameters for OpenEdge
|
The parameters for the connection to the source OpenEdge database, which is the current working database. Accept the default value.
|
|
Name of Schema holder Database
|
Enter the name for the schema holder. The utility creates the schema holder if it does not exist.
|
|
Logical name for Oracle Database
|
Enter the Oracle database logical name. The logical database name is the name of the schema image and the name you will use to refer to the Oracle database in applications. The database's logical name must be different than the name you enter for the schema holder and different than the name of any other schema image existing in that schema holder.
|
|
What version of Oracle
|
Enter the version of Oracle you are using. The default is 8. To enable Unicode, this value must be set to 9 or higher, which represents Version 9i or later.
|
|
Oracle Owner's Username
|
Enter the Oracle database owner's name.
|
|
Oracle User's password
|
Enter the owner's password.
|
|
Oracle connect parameters
|
Enter additional connection parameters as needed.
|
|
Code page for Schema Image
|
Enter the OpenEdge name for the code page that the Oracle Call Interface (OCI) uses. For Unicode support, set the value to UTF-8 when migrating from an OpenEdge database to an Oracle database.
Note: For a UTF-8 schema image code page, the corresponding OCI code page (that is, the NLS_LANG setting) setting must be AL32UTF8 to ensure full Unicode compatibility.
|
|
Collation Name
|
Enter the collation table you wish to use. By default, the collation table is Basic. The collation table you specify must be defined in the convmap .dat file or you will receive an error message.
|
|
Maximum char length
|
Enter a positive value up to and including 4000. This value is defaulted based on the values of other Unicode-specific settings in your migration. See Handling character length during database migration for details.
|
|
Tablespace tables
|
Enter the name of the Oracle tablespace where you want to store schema information. The default is the Oracle user's default tablespace.
|
|
Tablespace index
|
Enter the name of the Oracle tablespace where you want to store index information. The default is the Oracle user's default tablespace.
|
|
Load SQL
|
Check this toggle box to load the .sql file that contains the data definitions for your OpenEdge database into the Oracle database. By default, this option is checked.
|
|
Move Data
|
Check this toggle box to dump and load data from your OpenEdge database to the Oracle database. Copying data from a large database can take a long time. For example, you might not check this box if you want to dump and load data at a more convenient time.
|
|
Advanced
|
Click Advanced to open the ORACLE Conversion Advanced Options dialog box The purpose of this dialog box is to reduce clutter on the main dialog box and provide logical grouping of fields on it. See the table below for the details you must enter.
|
|
Interface Element
|
Description
|
|
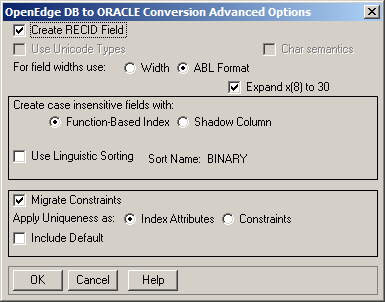
Create RECID field
|
Check this toggle box to create an Oracle database that supports arrays, case-insensitive indexes, backward and forward scrolling, and the OpenEdge record identifier. These objects result in additional columns added to Oracle tables.
|
|
Char semantics
|
Check this toggle box to set the unit of measure for length to character semantics when migrating OpenEdge file fields to Oracle table columns. Length values for the migration are derived from the For field widths use setting. The Char semantics option is only enabled for Unicode migrations. To enable it, the schema image code page must be set to utf-8 and you must specify an Oracle Version of 9 or later. The default setting is YES if ORACODEPAGE is UTF-8.
|
|
Use Unicode Types
|
Maps character fields to Unicode data types. You must specify 9 or higher (corresponding to an Oracle version of 9i or later) to enable this option.
|
|
For field widths use
|
When pushing fields to a foreign data source, you can select one of two primary field format options:
If you select the ABL Format option, you have an additional setting to define:
Note: You cannot use the Expand x(8) to 30 setting with the Width option.
|
|
Create case-insensitive fields with
|
Provides OpenEdge compatibility to case-insensitive data columns. To support case insensitivity, you must choose between the options, Function-Based Index (the default) and Shadow Column. When you select the Function-Based Index option, you can choose either the UPPER() or the NLS_UPPER() function; applied to indexes that include case-insensitive columns. The choice of which function to apply to indexes is made internally during migration, which depend upon the selection for Use Linguistic Sorting that follows this selection in the Advanced Options sub-section.
Select Shadow Column to support case-sensitive columns. This option is a legacy option for backward compatibility. By default, this option is not selected, allowing the utility to automatically support ABL case insensitivity via Oracle function-based indexes.
Note: Function-based indexes and shadow columns can co-exist in a schema holder to support case insensitive indexes.
|
|
Using Linguistic Sorting
|
Check this option to migrate the database with linguistic sorting. By default, the Linguistic Sorting option is disabled, and a binary sort is applied to code points. To use linguistic sorting, you must specify a Linguistic Sort Name that corresponds to a valid sort name in Oracle. This sort name is applied to all migrated indexes, which become NLS_SORT() function-based indexes.
If you select Function-Based Index for case-insensitivity of the same indexed columns, then the migrated indexes will be both NLS_UPPER and NLS_SORT function-based indexes
Information regarding the linguistic sorting is stored in the schema image. This information is used at the time of session connection to Oracle to set the session settings to NLS_SORT and NLS_COMP. Thus, the database session seamlessly utilizes the proper function-based indexes for sorting and matching record.
|
|
Migrate Constraints
|
Indicates how the constraint definitions are managed. By default, the Migrate Constraints box is checked. The Apply Uniqueness as: toggle allows you to choose between Indexes or constraint definitions as the method of enforcing uniqueness. Indexes is selected by default to maintain backward compatibility. Select Constraints to change the method of enforcing uniqueness.
|
|
Include Default
|
Check this toggle box to include initial values in column definitions.
|