
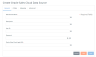
|
Field
|
Description
|
|
Data Source Name
|
A unique name for the data source. Data source names can contain only alphanumeric characters, underscores, and dashes.
|
|
Description
|
A general description of the data source.
|
|
User Id, Password
|
The login credentials for your Oracle Sales Cloud data store account.
Note: By default, the password is encrypted.
The Hybrid Data Pipeline connectivity service uses this information to connect to the data store. The administrator of the data store must grant permission to a user with these credentials to access the data store and the target data.
Note: You can save the Data Source definition without specifying the login credentials. In that case, when you test the Data Source connection, you will be prompted to specify these details. Applications using the connectivity service will have to supply the data store credentials (if they are not saved in the Data Source) in addition to the Data Source name and the credentials for the Hybrid Data Pipeline connectivity service.
By default, the characters in the Password field you type are not shown. If you want the password to be displayed in clear text, click the eye
 icon. Click the icon again to conceal the password. icon. Click the icon again to conceal the password.
|
|
Oracle Sales Cloud Login URL
|
The Host Name for the Oracle Sales Cloud site that the Hybrid Data Pipeline connectivity service will use to query the service; for example, mysite.custhelp.com.
|
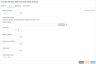
|
Field
|
Description
|
|
OData Version
|
Enables you to choose from the supported OData versions. OData configuration made with one OData version will not work if you switch to a different OData version. If you want to maintain the data source with different OData versions, you must create different data sources for each of them.
|
|
OData Access URI
|
Specifies the base URI for the OData feed to access your data source, for example, https://hybridpipe.operations.com/api/odata/<DataSourceName>. You can copy the URI and paste it into your application's OData configuration.
The URI contains the case-insensitive name of the data source to connect to, and the query that you want to execute. This URI is the OData Service Root URI for the OData feed. The Service Document for the data source is returned by issuing a GET request to the data source's service root.
The OData Service Document returns the names of the entities exposed by the Data Source OData service. To get details such as the properties of the entities exposed, the data types for those properties and the relationships between entities, the Service Metadata Document can be fetched by adding /$metadata to the service root URI.
|
|
Schema Map
|
Enables OData support. If a schema map is not defined, the OData API cannot be used to access the data store using this data source definition. Use the Configure Schema editor to select the tables/columns to expose through OData.
See Configuring data sources for OData connectivity and working with data source groups for more information.
|
|
Page Size
|
Determines the number of entities returned on each page for paging controlled on the server side. On the client side, requests can use the $top and $skip parameters to control paging. In most cases, server side paging works well for large data sets. Client side pagination works best with a smaller data sets where it is not as expensive to fetch subsequent pages.
Valid Values: 0 | n
where n is an integer from 1 to 10000.
When set to 0, the server default of 2000 is used.
Default: 0
|
|
Refresh Result
|
Controls what happens when you fetch the first page of a cached result when using Client Side Paging. Skip must be omitted or set to 0. You can use the cached copy of that first page, or you can re-execute the query to get a new result, discarding the previously cached result. Re-executing the query is useful when the data being fetched may change between two requests for the first page. Using the cached result is useful if you are paging back and forth through results that are not expected to change.
Valid Values:
When set to 0, the OData service caches the first page of results.
When set to 1, the OData service re-executes the query.
Default: 1
|
|
Inline Count Mode
|
Specifies how the connectivity service satisfies requests that include the $count parameter when it is set to true (for OData version 4) or the $inlinecount parameter when it is set to allpages (for OData version 2). These requests require the connectivity service to include the total number of entities that are defined by the OData query request. The count must be included in the first page in server-driven paging and must be included in every page when using client-driven paging.
The optimal setting depends on the data store and the size of results. The OData service can run a separate query using the count(*) aggregate to get the count, before running the query used to generate the entities. In very large results, this approach can often lead to the first page being returned faster. Alternatively, the OData service can fetch the entire result before returning the first page. This approach works well for small results and for data stores that cannot optimize the count(*) aggregate; however, it may have a longer initial response time for the first page if the result is large.
Valid Values:
When set to 1, the connectivity service runs a separate count(*) aggregate query to get the count of entities before executing the query to return results. In very large results, this approach can often lead to the first page being returned faster.
When set to 2, the connectivity service fetches all entities before returning the first page. For small results, this approach is always faster. However, the initial response time for the first page may be longer if the result is large.
Default: 1
|
|
Top Mode
|
Indicates how requests typically use $top and $skip for client side pagination, allowing the service to better anticipate how to process queries.
Valid Values:
Set to 0 when the application generally uses $top to limit the size of the result and rarely attempts to get additional entities by combining $top and $skip.
Set to 1 when the application uses $top as part of client-driven paging and generally combines $top and $skip to page through the result.
Default: 0
|
|
OData Read Only
|
Controls whether write operations can be performed on the OData service. Write operations generate a 405 Method Not Allowed response if this option is enabled.
Valid Values:
ON | OFF
When ON is selected, OData access is restricted to read-only mode.
When OFF is selected, write operations can be performed on the OData service.
Default: OFF
|
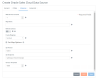
|
Field
|
Description
|
||||||||
|
Web Service Call Limit
|
The maximum number of Web service calls allowed to the cloud data store for a single SQL statement or metadata query.
Valid Values: -1 | 0 | x
where x is a positive integer that defines the maximum number of Web service calls that the connectivity service can make when executing any single SQL statement or metadata query.
If set to -1, the connectivity service uses the default value that is configured in the service when connected to a site whose version is August 2014 or later. When connected to sites whose version is prior to August 2014, the connectivity service sets the maximum number of calls to 100.
If set to 0, the connectivity service uses the maximum number of calls allowed by the service when connected to a site whose version is August 2014 or later. When connected to sites whose version is prior to August 2014, there is no limit.
If set to x, the connectivity service uses this value to set the maximum number of Web service calls that can be made when executing a SQL statement or metadata query. If you specify a value that is greater than the maximum number of calls allowed when connected to a site whose version is August 2014 or later, the connectivity service returns a warning and uses the maximum value instead.
Default: -1.
|
||||||||
|
Map Name
|
Optional name of the map definition that the Hybrid Data Pipeline connectivity service uses to interpret the schema of the data store. The Hybrid Data Pipeline service automatically creates a name for the map.
|
||||||||
|
Refresh Schema
|
Specifies whether the Hybrid Data Pipeline connectivity service attempts to refresh the schema when an application first connects.
Valid Values:
ON | OFF
If set to OFF and the ResultSetMetaData.getTableName() method is called, the connectivity service does not perform additional processing to determine the correct table name for each column in the result set. The getTableName() method may return an empty string for each column in the result set.
If set to ON and the ResultSetMetaData.getTableName() method is called, the connectivity service performs additional processing to determine the correct table name for each column in the result set. The connectivity service returns schema name and catalog name information when the ResultSetMetaData.getSchemaName() and ResultSetMetaData.getCatalogName() methods are called if the connectivity service can determine that information.
Default: OFF
|
||||||||
|
Create Mapping
|
Determines whether the Oracle Sales Cloud table mapping files are to be (re)created.
The Hybrid Data Pipeline connectivity service automatically maps data store objects and fields to tables and columns the first time that it connects to the data store. The map includes both standard and custom objects and includes any relationships defined between objects.
|
||||||||
|
API Version
|
Identifies the version of Oracle Sales Cloud used in your environment.
By default, API Version is set to latest. When set to latest, the connectivity service assumes the latest version of Oracle Sales Cloud is being used.
API Version can also be set to a specific Oracle Sales Cloud API version, for example, 11.1.11.
|
||||||||
|
API Endpoints
|
Specifies modules for Oracle Sales Cloud instances. The Hybrid Data Pipeline connectivity service retrieves resources from the specified endpoints. Modules must be separated by a comma.
Default: salesApi,crmCommonApi
|
||||||||
|
Varchar Threshold
|
Specifies the threshold at which columns of the data type SQL_VARCHAR are described as SQL_LONGVARCHAR. If the size of the SQL_VARCHAR column exceeds the value specified, the column is described as SQL_LONGVARCHAR when calling SQLDescribeCol and SQLColumns. This option allows you to fetch columns that would otherwise exceed the upper limit of the SQL_VARCHAR type for some third-party applications.
Default: 4000
|
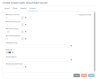
|
Field
|
Description
|
|
Web Service Fetch Size
|
Specifies the number of rows of data the Hybrid Data Pipeline connectivity service attempts to fetch for each Web service call.
Valid Values:
0 | x
If set to 0, the connectivity service attempts to fetch up to a maximum of 100 rows. This value typically provides the maximum throughput.
If set to x, the connectivity service attempts to fetch up to a maximum of the specified number of rows. Setting the value lower than 100 can reduce the response time for returning the initial data. Consider using a smaller value for interactive applications only.
Default: 100
|
|
Web Service Retry Count
|
The number of times to retry a timed-out Select request. Insert, Update, and Delete requests are never retried. The Web Service Timeout parameter specifies the period between retries. A value of 0 for the retry count prevents retries. A positive integer sets the number of retries. The default value is 0.
|
|
Web Service Timeout
|
The time, in seconds, to wait before retrying a timed-out Select request. Valid only if the value of Web Service Retry Count is greater than zero. A value of 0 for the timeout waits indefinitely for the response to a Web service request. There is no timeout. A positive integer is considered as a default timeout for any statement created by the connection. The default value is 120.
|
|
Max Pooled Statements
|
The maximum number of prepared statements to cache for this connection. If the value of this property is set to 20, the connectivity service caches the last 20 prepared statements that are created by the application.
Default: 0
|
|
Initialization String
|
A semicolon delimited set of commands to be executed on the data store after Hybrid Data Pipeline has established and performed all initialization for the connection. If the execution of a SQL command fails, the connection attempt also fails and Hybrid Data Pipeline returns an error indicating which SQL commands failed.
Syntax:
SQLcommand[[; SQLcommand]...]
where:
SQLcommand is a SQL command. Multiple commands must be separated by semicolons.
Default: an empty string.
|
|
Read Only
|
Enables write operations to Oracle Sales Cloud.
If set to ON, the data source is read only. Write operations are not allowed.
If set to OFF), write operations are permitted if Oracle Sales Cloud Database is set to operational. Write operations are not supported if Oracle Sales Cloud Database is set to report.
Default: ON
|
|
Extended Options
|
Specifies a semi-colon delimited list of connection options and their values. Use this configuration option to set the value of undocumented connection options that are provided by Progress DataDirect technical support. You can include any valid connection option in the Extended Options string, for example:
Database=Server1;UndocumentedOption1=value[;UndocumentedOption2=value;]
If the Extended Options string contains option values that are also set in the setup dialog, the values of the options specified in the Extended Options string take precedence.
Valid Values: string
Default: empty string
If you are using a proxy server to connect to your Sales Cloud instance, then you have to set these options:
proxyHost = hostname of the proxy server; proxyPort = portnumber of the proxy server
If Authentication is enabled, then you have to include the following:
proxyuser=<value>; proxypassword=<value>
|
|
Metadata Exposed Schemas
|
Restricts the metadata exposed by Hybrid Data Pipeline to a single schema. The metadata exposed in the SQL Editor, the Configure Schema Editor, and third party applications will be limited to the specified schema. JDBC, OData, and ODBC metadata calls will also be restricted. In addition, calls made with the Schema API will be limited to the specified schema.
Warning: This functionality should not be regarded as a security measure. While the Metadata Exposed Schemas option restricts the metadata exposed by Hybrid Data Pipeline to a single schema, it does not prevent queries against other schemas on the backend data store. As a matter of best practice, permissions should be set on the backend data store to control the ability of users to query data.
Valid Values
<schema>
Where:
<schema>
is the name of a valid schema on the backend data store.
Default: No schema is specified. Therefore, all schemas are exposed.
|