Configuring data sources for OData Version 4 connectivity
Hybrid Data Pipeline supports OData Version 2 and Version 4 connectivity for all supported data stores. You can configure a data source on any data store for OData connectivity either during the process of creating the data source or after the data source has been created.
The following steps describe how to configure a data source for OData Version 4 connectivity.
1. From the Web UI, navigate to the Data Sources view by clicking the data sources icon .
Option 1. If creating a new data source, click New Data Source, choose the data store, enter the required information on the General tab, and click TEST to confirm connectivity to the backend data store. (See Creating data sources with the Web UI for details.)
Option 2. If enabling OData on an existing data source, select the data source you wish to modify.
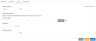
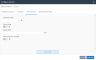
2. Select the OData tab.
Click the thumbnail to view the screen
3. For OData Version, select Version 4.
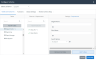
4. Open the Configure Schema editor by clicking Configure to the right of the Schema Map field.
Click the thumbnail to view the screen
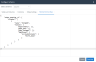
5. Select a schema from the Select Schema dropdown.
Note: By default, Hybrid Data Pipeline exposes all schemas on any backend data stores that support multiple schemas. The Metadata Exposed Schemas option on the Advanced tab for any such data store can be used to limit exposed schemas to a single schema. If a schema is selected for the Metadata Exposed Schemas option, it will be the only schema available on the Configure Schema editor's Select Schema dropdown.
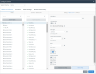
6. From the Tables and Columns tab, select and define the tables and columns you want to expose to OData client applications.
To add all tables, click Add All Tables on the Tables panel.
To add individual tables, select a table on the Tables panel and click Add To Map in the Settings panel to the right.
To remove a table that was previously added, select the table and click Remove From Map in the Settings panel.
To specify singular and plural alias names for a table, select the table, enter the table alias for the entity type name in the Singular Name field, enter the table alias for the entity collection name in the Plural Name field, and click Add To Map.
The singular alias name specified is used as the entity type name, while the plural alias name will be used as the entity collection name. When alias names are not specified, the mapping of entity names will be dictated by the Entity Name Mode setting in the OData Settings tab, as described in Step 9.
To specify a column as a primary key, select the column from the Columns panel and set the Is Primary Key switch from OFF to ON.
The Configure Schema editor indicates that a primary key exists for a table with a star icon. A primary key assigned in the backend data store cannot be changed. If a primary key has not been discovered for a table you wish to map, one or more columns must be specified as a primary key.
To remove a column from the OData schema map, select the column from the Columns panel and click Remove From Map in the Settings panel.
When a table is added, all columns in the table are exposed in the OData schema map by default. You can modify the columns exposed by removing (or excluding) them from the schema map.
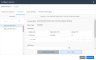
7. From the Tables and Columns tab, select the columns you want to view or modify.
Click the thumbnail to view the screen
To specify an alias name for a column, select the column and enter an alias in the Alias Name field. If specified, the alias name will be used as the OData name for the column. If not specified, the name of the column will be used as the OData name.
To specify a column as a primary key, set the Is Primary Key switch from OFF to ON.
The Configure Schema editor indicates that a primary key exists for a table with a star icon. A primary key assigned in the backend data store cannot be changed. If a primary key has not been discovered for a table you wish to map, one or more columns must be specified as a primary key.
Open Advanced Settings to review and modify column metadata. The Advanced Settings allow you to modify column metadata returned by the underlying JDBC driver. This is especially useful when the JDBC driver returns incorrect metadata. The Driver Value of each setting indicates the value that is returned by the driver. You can specify settings related to the following properties:
Data Type: Indicates the data type for the column. If you wish to use the Actual Value, you can leave the Data Type as Default. If you wish to override the data type specified, you can choose an alternate data type from the dropdown list.
Depending on the data types selected, some of the Advanced settings options will be enabled or disabled. For example, Scale is enabled for the decimal datatype, and not for the integer datatype.
Column Size or Precision: Indicates the maximum precision or maximum length of the column.
Scale: Indicates the maximum scale of the column.
Is Nullable: Indicates whether the column can have a null value. Normally drivers report this correctly. Some drivers may report a column as not nullable while null values exist in the column. In such a scenario, the is Nullable could be set to true to correct this issue. Note that there could be implications on the create entity behavior by changing this setting.
Is Auto Increment: Indicates whether the column is a uniquely generated column. Setting this to true will indicate to the service that it should ignore incoming values for this column during the create, update, and patch entity operations.
Is Generated: Indicates whether the column is a generated value. If the column is generated, then the OData code will ignore incoming values for this column during the create, update, and patch entity operations.
8. Take the following steps to enable text search for individual tables and text-based columns using the $search system query option.
a. Select a table from the Tables panel.
b. Specify a search option from the Search Options dropdown. Then click Add To Map.
Full Text is only available for data store types that support indexing and full text search.
Substring enables searches for the string anywhere in the search-enabled fields.
Begins restricts the search to the text at the beginning of a field.
c. If you selected Full Text in Step b, you should select an index type for all text-based columns. Select the column from the Columns panel, and specify an index type from the Index Type dropdown in the Settings panel. Then click Add To Map.
The index type is the type of index supported by the backend data store. TEXT is the only valid value for the DB2 and SQL Server data stores. CONTEXT and CTXCAT are the valid values for the Oracle data store. If Full Text has been selected but the data store index has not been properly configured, queries using $search will return errors.
d. If you selected Substring or Begins in Step b, you should select which text-based columns can be searched. Select the column from the Columns panel, and set the Is Searchable switch to ON. Then click Add To Map.
9. Take the following steps to expose stored functions.
Note: Stored functions are supported only for DB2, Oracle, PostgreSQL, and SQL Server data stores. See Stored functions support for details on further restrictions.
Click the thumbnail to view the screen
a. Select the Functions tab.
b. Select the function you want to expose from the Functions panel.
c. If desired, specify an alias name for the stored function.
d. If desired, specify an import alias name for a function import that corresponds to the function.
e. Specify whether the OData type is a function or an action on the OData Type dropdown.
f. Click Add To Map.
10. Specify general settings on the OData Settings tab. Then click Add To Map to apply settings.
Click the thumbnail to view the screen
From the Entity Name Mode dropdown, specify the algorithm used to map table names to entity collection names or entity type names. Entity collection names are usually plural, while entity type names are usually singular.
When guess (default) is selected, one of the following algorithms is applied based on an evaluation of the table name.
▪ If the table name ends with a numeric digit, the table name is used as the entity collection name and a suffix is appended to the table name for the entity type name. The suffix used can be specified in the Singular Suffix field.
▪ If the table name does not end with a digit and appears to be singular, the table name is used as the entity collection name and singularized for the entity type name.
▪ If the table name does not end with a digit and appears to be plural, the table name is used as the entity type name and pluralized for the entity collection name.
When singularize is selected, the table name is used as the entity collection name. The table name is then singularized for the entity type name.
When pluralize is selected, the table name is used as the entity type name. The table name is then pluralized for the entity collection name.
When suffix is selected, the table name is used as the entity collection name. For the entity type name, a suffix is appended to the table name. The suffix used can be specified in the Singular Suffix field.
With the Time As String switch, specify how the JDBC type Time should be mapped.
If set to OFF (default), Time is mapped to the OData type TimeOfDay.
If set to ON, Time is mapped as String.
In the Singular Suffix field, enter the suffix that will be appended to an entity type name when the Entity Name Mode has been set to either guess or suffix.
With the Unbound Number as Double switch, specify whether decimal columns and parameters with no precision or scale should be automatically mapped as Double.
If set to OFF (default), decimal columns and parameters with no precision or scale are not automatically mapped as Double.
If set to ON, decimal columns and parameters with no precision or scale are automatically mapped as Double.
11. Click the Review Schema Map tab to review the OData schema map in JSON format.
Click the thumbnail to view the screen
12. Click Save Map to save your configuration of the OData schema map.
13. Set OData options to the desired values.
Data Source Caching controls caching of results. A value of 0 results in a stateless session, requiring Hybrid Data Pipeline to access the data store for each request. A value of 1, the default, allows Hybrid Data Pipeline to cache results, improving performance for repeated requests for the same entity. Hybrid Data Pipeline clears the cache after ten minutes of inactivity or at the end of a session.
Page Size controls the number of results returned in one response. By default, the value in this field is 0 which causes Hybrid Data Pipeline to return up to 2,000 top-level entities per response. If the response contains more than 2,000 entities, the first 2,000 entities are returned and the end of the response contains a link that the OData client can use to fetch the next set. You can set the page size by using values from 1 to 10,000. Client requests can also specify the size of results with query parameters.
Refresh Result determines whether Hybrid Data Pipeline returns results from the cache (for entities in the cache) or queries the data source again. A value of 1, the default, allows Hybrid Data Pipeline to satisfy requests from cached results. A value of 0 forces queries to the backend data store. If caching is not enabled, this parameter has no effect.
Inline Count Mode controls how Hybrid Data Pipeline handles requests that include the $inlinecount parameter with a value of allpages. The response includes the total number of entities that satisfy the query. A value of 0 causes Hybrid Data Pipeline to skip counting. A value of 1 causes Hybrid Data Pipeline to run a separate query to get the count before the query that returns the entities. This can result in the first page of results being returned faster for large result sets for some data store types. A value of 2, the default, causes Hybrid Data Pipeline to fetch all results and calculate the total number before returning the first page of results to the client.
Top Mode allows Hybrid Data Pipeline to better handle requests that include the $top parameter. A value of 0, the default, indicates that clients using $top to limit result set size will rarely attempt to get additional entities using the $skip parameter. A value of 1 indicates that clients generally use $top and $skip together to paginate results.
OData Read Only controls read/write access. For a new data source definition, this option is not selected by default. For a data source definition where OData was enabled before this option was available, it will be checked by default. Remove the check mark to enable write access.
After you create an OData-enabled data source, you can view the status of the schema map generation on the Data Sources screen. The icon besides the OData-enabled data source indicates the status of the schema map generation. The following table provides details of the icons.
Icon
Description
The synchronization of the schema map is in progress. The number denotes the percentage of synchronization completed.
The schema map was synchronized successfully.
The schema map was synchronized successfully, but there are some table/column warnings. Hybrid Data Pipeline allows users to know the details of the tables/columns and/or functions that were dropped while generating the OData Model for a given schema map of a Data Source. The number of warnings shown is limited to 100. If there are more than 100 errors/warnings, you can use the Schema API to retrieve table and column warnings.
Errors occurred while synchronizing the schema map. You must address the errors and synchronize the schema map again. Hybrid Data Pipeline allows users to know the details of the tables and/or columns that were dropped while generating the OData Model for a given schema map of a Data Source. The number of errors/warnings shown is limited to 100. If there are more than 100 errors/warnings, you can use the Schema API to retrieve table and column warnings.

 .
.