|
pro -p prodict/mss/schpullmss.p |
|
Interface element
|
Description
|
|
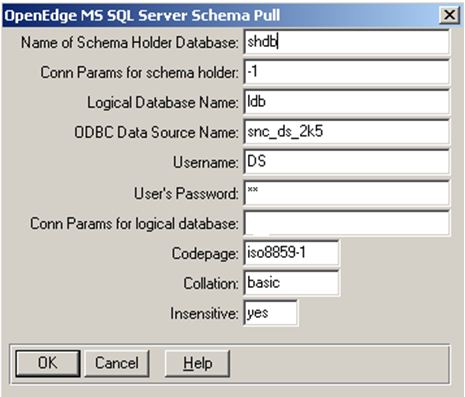
Name of Schema holder Database
|
Default: <blank>
Specifies a schema holder name of your choice.
Dependencies: If a schema holder database is not set, the pull operation cannot proceed.
|
|
Connect parameters for schema holder
|
Default: <Schema holder of current working database>
Specifies the startup parameters for the schema holder pull process.
For more information on connection parameters, see Connectingthe DataServer for connection parameters.
Dependencies: By default, the schema holder is started in multi-user. Therefore, if you provide your own connect parameters for schema holder, you must include settings to connect the run the schema holder in the single-user mode or read-only mode to avoid connection failure.
|
|
Logical Database Name
|
Default: <blank>
Specifies a MSS logical database associated with the schema image from the pull process.
OpenEdge identifies the MS SQL Server database using the logical database name.
Dependencies: If the logical database name is not set, the pull operation cannot proceed.
The Logical Database Name must be different from the Name of the Schema Holder Database.
|
|
ODBC Data Source Name
|
Default: <blank>
Specifies the ODBC Data Source Name you used when registering the data source.
Dependencies: If the ODBC Data Source Name is not set, the pull operation cannot proceed.
The value for ODBC Data Source Name must be different from the Name of the Schema Holder Database.
The ODBC DNS must be properly specified in the ODBC Data Source Administrator of your system. If the Load SQL interface element is set to YES, ODBC DNS must also be properly configured to connect to the foreign Data Source.
|
|
Username
|
Default: <blank>
Specifies the user ID for MS SQL Server.Dependencies: If you do not set the user name that is required for authentication, the pull operation terminates with an error.
|
|
User's Password
|
Default: <blank>
Specifies the password of the user.
Dependencies: If you do not set the password that is required for authentication, the pull operation terminates with an error.
|
|
Connect parameters for logical database
|
Default: <current working database>
Specifies the startup parameters for the schema holder and the foreign data source connection.
For more information on connection parameters, see Connectingthe DataServer for connection parameters.
Dependencies: Connect parameters are not mandatory. If supplied, they must be formatted as a comma-separated list of names or name-value pairs, without white-spaces, that comprise the -Dsrv parameter value passed to the DataServer connection. Some of the parameters are parsed into the DataServer run-time, while others in the list are forwarded onto the target foreign data source.
If an invalid or improperly formatted connection parameter is parsed during migration, the pull operation terminates with an error.
|
|
Codepage
|
Default: iso8859-1 when UNICODETYPES is disabled (that is, set to NO).
Specifies the corresponding OpenEdge name for the code page with which the MSS Database is compatible. Use UTF-8 if Unicode support is desired.
If you use a code page that OpenEdge does not support, you must supply a conversion table that translates between the OpenEdge client code page and the code page that your data source uses. For a complete discussion of code pages, see OpenEdge Development: Internationalizing Applications.
Dependencies: The specified codepage must exist in the convmap.cp file of your Progress environment in order to be used during the pull operation.
|
|
Collation
|
Default: Basic
Specifies the collation name with which the schema holder must collate and weigh code page values.
Dependencies: The specified collation must exist in the convmap.cp file of your Progress environment in order to be used during the migration unless you are using a Unicode code page. In case you are using a Unicode code page, then the code page name can correspond to one of the International Components for Unicode (ICU) collations that provide linguistic sorting of Unicode data based on the Unicode Collation Algorithm.
|
|
Insensitive
|
Default: NO
Specifies if the code page you use is or isn't case insensitivity. Provide YES if your code page is case insensitive, else retain the default value NO.
Dependencies: By default, the code pages in MS SQL Server are case-insensitive. This matches the default sensitivity in OpenEdge. So, if you are using a case-insensitive code page in MS SQL Server, Progress recommends setting this value to YES.
|
|
Interface element
|
Description
|
|
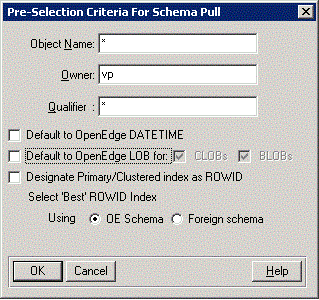
Object name
|
Default: *
Specify an Object name qualifier for objects to be pulled for the server. The wild card default selects all objects. For example, you can specify A* in the Object Name field to list all the tables whose names begin with A or a.
Note: You should not specify an entry that consists exclusively of wild cards for each of the three entry fields in the dialog box. An entry that consists exclusively of wild cards might degrade the performance of the database when you perform a schema pull. (It will include system catalog files from the data source not typically included in user databases.)
|
|
Owner
|
Default: owner name of the connected user
Specify an Object owner to be pulled for the server. The wild card default selects all objects. For example, you can specify DS* in the Ownerfield to list all the tables whose names begin with A or a.
Note: You should not specify an entry that consists exclusively of wild cards for each of the three entry fields in the dialog box. An entry that consists exclusively of wild cards might degrade the performance of the database when you perform a schema pull. (It will include system catalog files from the data source not typically included in user databases.)
|
|
Qualifier
|
Default: *
Specify an Object's qualifying database name to be pulled for the server. The wild card default selects all objects.
Note: You should not specify an entry that consists exclusively of wild cards for each of the three entry fields in the dialog box. An entry that consists exclusively of wild cards might degrade the performance of the database when you perform a schema pull. (It will include system catalog files from the data source not typically included in user databases.)
|
|
Default to OpenEdge DATETIME
|
Default: NO or unchecked
When set to YES, this automatically maps MS SQL Server timestamp data types to the associated OpenEdge equivalent DATETIME data type.
When set to NO, server timestamp data types map to DATE data type in OpenEdge for backward compatibility.
|
|
Default to OpenEdge LOB for:
|
Default: NO or unchecked
By default, the unchecked box indicates that all server LOB data types will map to CHARACTER data types in OpenEdge for backward-compatibility.
Check this box to enable the mapping of MS SQL Server LOB types to OpenEdge LOB's. NOTE: By checking this box you are requiring that your ABL application be coded specifically to handle LOB objects with OpenEdge LOB operations. Check the CLOBs checkbox in order to map MS SQL Server VARCHAR(MAX) and TEXT data types to OpenEdge CLOBS.
Check the BLOBs checkbox in order to map MS SQL Server VARBINARY(MAX), IMAGE and FILESTREAM data types to OpenEdge BLOBs to MS SQL Server VARBINARY(MAX), IMAGE and FILESTREAM data types.
Else, all server LOB data types map to the CHARACTER data type in OpenEdge for backward-compatible.
Caution: If you select YES, it enables the use of LOB objects in the ABL language for LOBs in the foreign schema but also disables compatibility with the original OpenEdge database and will cause an Adjust Schema operation to fail.
For more information on mapping OpenEdge and MS SQL Server data types, see Support for OpenEdge ABL BLOB data type.
|
|
Designate Primary/Clustered index as ROWID
|
Default: NO
Specifying YES designates the clustered index as ROWID if it qualifies for ROWID selection for a table with a defined clustered index and without a defined PROGRESS_RECID field.
Dependencies: For the clustered index to qualify for ROWID selection, it must be unique. For legacy purposes, if the server table is identified as having a PROGRESS_RECID field, this setting takes precedence over other settings for ROWID selection.
|
|
Select 'Best' ROWID Index
|
Selecting Select 'Best' ROWID Index during migration provides the legacy equivalent of ROWID designation behavior for the tables from prior versions of OpenEdge where the PROGRESS_RECID column was not present in a table.
When selected in conjunction with new process flow options for ROWID migration, this option plays a secondary role in the designation of ROWID indexes deferring to the Designate Primary/Clustered index as ROWID option as the first choice. This option searches for a viable index for ROWID when an PROGRESS_RECID column does not exist and other process flow options that take precedence do not render a viable index.
Select 'Best' ROWID Index using one of the following options:
Dependencies: For legacy purposes, if the server table is identified as having a PROGRESS_RECID field, this setting takes precedence over other settings for ROWID selection. Also, if clustered and primary index ROWID mapping is also selected via the SETROWID variable, then the SETROWID variable takes precedence over GETBESTROWID for ROWID selection.
|