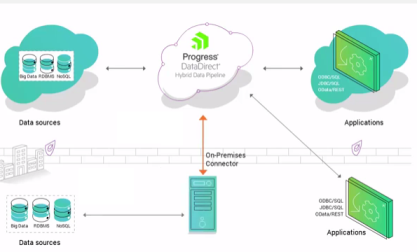
Progress® DataDirect® Hybrid Data Pipeline is a light weight software service that is designed to allow applications to access data from data sources that are in the cloud or on-premises. Your application can use a single API – ODBC, JDBC, or OData – to access any of the data source types we support – cloud, SQL, Big Data, and NoSQL.
Exposing a backend data store to applications using Hybrid Data Pipeline requires configuration in the Hybrid Data Pipeline user interface and in the consuming applications. Applications communicate with Hybrid Data Pipeline through JDBC, ODBC, or OData. Hybrid Data Pipeline translates their requests into the format supported by the underlying data store and returns the response in the format accepted by the client.
When Hybrid Data Pipeline is installed in the cloud, you use the On-Premises Connector to access databases that reside behind the firewall.
Preparation
Have the following information ready:
The credentials to log into your data stores, such as DB2, Microsoft SQL Server, Oracle Service Cloud, and Oracle Sales Cloud.
Connection information for the client applications that will access data through Hybrid Data Pipeline. For example, some business intelligence (BI) tools, reporting tools, and custom applications, support JDBC, ODBC, or OData out-of-the-box. For applications that can use OData with a REST API, no additional driver is required.
To use JDBC or ODBC to access your backend data source, you need to install a local driver that connects the apps with Hybrid Data Pipeline. The driver is a small component that installs quickly.
See Before you start for the system requirements for the Hybrid Data Pipeline components.