

|
Environment variable
|
Interface element
|
Description
|
|
PRODBNAME
|
Original OpenEdge Database
|
Default: <blank>
Specify the source OpenEdge database name to be migrated.
If this environment variable is not set and if the user has already set a current working database, the command line migration uses this as the value for the original OpenEdge database.
Dependencies: If PRODBNAME is not set, and no working database is connected prior to running the conversion utility then the migration terminates, and an error is thrown in the logs.
|
|
PROCONPARMS
|
Connect parameters for OpenEdge
|
Default: Current working database parameters
Specifies startup parameters for the original OpenEdge source database.
If this environment variable is not set and if the user has already set a current working database, the command line migration uses the parameters that were associated with the startup of the original OpenEdge database specified by the PRODBNAME environment variable. You can specify your own startup parameters for the connection to the source OpenEdge database with this environment variable.
Dependencies: The connection parameters associated with the source OpenEdge database, named by PRODBNAME, is specified by and connected with the PROCONPARMS environment variable value, along with the single-user mode (-1) parameter. In single-user mode, only one user can access the database. It is required that the PRODBNAME source database be started in a single-user mode for successful batch migration so that a snapshot of the database is used during the conversion.
If you provide your own PROCONPARMS value, it must include settings to connect PRODBNAME in single-user mode or in read-only mode (-RO). Otherwise, the database connection fails with an error. For more information, see OpenEdge Deployment: Startup Command and Parameter Reference.
|
|
SHDBNAME
|
Name of Schema holder Database
|
Default: <blank>
Specify the new schema-holder name, in which the resultant logical database will reside.
Dependencies: If SHDBNAME is not set, the migration terminates with an error.
|
|
MSSDBNAME
|
ODBC Data Source Name
|
Default: <blank>
Specify the ODBC Data Source name associated with the resultant schema image from the migration.
Dependencies: If MSSDBNAME is not set, the migration terminates with an error. The ODBC DSN must be properly specified and located in the ODBC Data Source Administration of your system.
If the Load SQL environment variable is set to YES, it must be properly configured to connect to the foreign data source.
|
|
MSSPDBNAME
|
Logical Database Name
|
Default: <blank>
Specify the Logical Database name configured to connect the foreign data source.
Dependencies: If MSSPDBNAME is not set, the migration terminates with an error. The value for MSSPDBNAME can be the same as PRODBNAME but must be different from SHDBNAME.
|
|
MSSUSERNAME
|
Username
|
Default: <blank>
Specify the user name for the target data source.
Dependencies: If MSSUSERNAME is not set, the migration terminates with an error.
|
|
MSSPASSWORD
|
User's Password
|
Default: <blank>
Specify the password of the user for the target data source.
Dependencies: If a password is required for authentication and MSSPASSWORD variable is not set, the migration terminates with an error. The error is logged in protomss.log.
|
|
MSSCONPARMS
|
Connect parameters
|
Default: <blank>
Specifies the startup parameters for the DataServer and the target foreign data source.
For more information on connection parameters, see Connectingthe DataServer for connection parameters.
Dependencies: Connect parameters are not mandatory. If supplied, they must be formatted as a comma-separated list of names or name-value pairs, without white-spaces, that comprise the -Dsrv parameter value passed to the DataServer connection. Some of the parameters are parsed into the DataServer run-time, while others in the list are forwarded onto the target foreign data source.
|
|
VARLENGTH
|
MaximumVarchar Length
|
Default: The unconditioned default is 8000. It ranges from 4000 to 8000.
Specify the maximum number of characters for a VARCHAR type. When a single-byte character set is utilized, as determined by the selected MSSCODEPAGE value, this must be a positive value less than or equal to 8000. The default threshold value of 8000 is the maximum number of characters that can be stored in a VARCHAR data type in MS SQL Server. When Unicode character data is utilized by virtue of a Unicode CODEPAGE environment variable selection, the default threshold value is limited to 4000. This value can also be overridden. During OpenEdge to MS SQL Server migration, whenever the column length of character data exceeds the value specified for VARLENGTH, the column is instead migrated as a Large Object (LOB) data type that can store data that far exceeds the data that can be stored in a VARCHAR data type.
Dependencies: When MSSCODEPAGE is set to utf-8, the value set for VARLENGTH must be a positive value less than or equal to 4000 as it is the maximum number of characters that can be stored in a NVARCHAR data type in MS SQL Server due to UCS-2 character expansion. And, character lengths exceeding the threshold value set for VARLENGTH are converted to Unicode Large Object types.
When an OpenEdge database stores UTF-8 data, each OpenEdge character can be as large as 4 bytes, potentially reducing the Maximum Varchar Length to 2000 characters on the server. But generally, MS SQL Server only supports the UCS-2 character set that allows 4000 UTF-8 characters in the UCS-2 range to be migrated into a Varchar column on the server.
|
|
MSSCODEPAGE
|
Codepage
|
Default: iso8859-1 when UNICODETYPES is disabled (that is, set to NO). Else, the default is utf-8.
Specifies the corresponding OpenEdge name for the code page with which the MSS Database is compatible. Use UTF-8 if Unicode support is desired.
If you use a code page that OpenEdge does not support, you must supply a conversion table that translates between the OpenEdge client code page and the code page that your data source uses. For a complete discussion of code pages, see OpenEdge Development: Internationalizing Applications.
It is not mandatory to pass this value during batch migration. You can use Change DataServer Schema Code Page utility to add the code page information to the schema holder later but before you start using the DataServer to read and write data. For more information on changing code page, see Changing a code page in a schema holder.
Dependencies: The specified codepage must exist in the convmap.cp file of your Progress environment in order to be used during the migration.
|
|
MSSCOLLNAME
|
Collation
|
Default: Basic
Specifies the collation name with which the OpenEdge client must collate and weigh code page values.
Dependencies: The specified collation must exist in the convmap.cp file of your Progress environment in order to be used during the migration unless you are using a Unicode code page. In case you are using a Unicode code page, then the code page name can correspond to one of the International Components for Unicode (ICU) collations that provide linguistic sorting of Unicode data based on the Unicode Collation Algorithm.
|
|
MSSCASESEN
|
Insensitive
|
Default: NO
Specifies if the code page you are matching on the foreign data source is or isn't case insensitive. Provide YES if your code page is case insensitive, else retain the default value NO.
Dependencies: By default, the code pages in MS SQL Server are case-insensitive. This matches the default sensitivity in OpenEdge. So, if you are using a case-insensitive code page in MS SQL Server, Progress recommends setting this value to YES.
|
|
LOADSQL
|
Load SQL
|
Default: NO
Allows you to specify whether you want the utility to execute the SQL script that is generated in order to create the schema in the target empty MS SQL Server database on the server that was configured through your ODBC Data Source Name. Specify YES to enable this behavior.
|
|
MOVEDATA
|
Move Data
|
Default: NO
Allows you to specify whether to populate the foreign data source with your OpenEdge data. Specify YES to dump and load data or NO to not populate the database. For example, you might specify NO if your database is large, and you want to dump and load data at a more convenient time.
Dependencies: Load SQL must be selected in order to move data.
|
|
Environment variable
|
Description
|
|
USE_OE_INIT_VALUE
|
This variable bypasses legacy migration behavior in which the OpenEdge default initial value for character fields, the NIULL string("") is ignored. Instead, you can set the USE_OE_INIT_VALUE to "Yes" to have a field with a null string("") as the OpenEdge initial value converted to the null string("") in SQL Server. Setting the value of USE_OE_INIT_VALUES to "Yes" impacts the migration only if Include Defaults is checked.
Note: The OpenEdge Initial Value of a null string ("") is applied to any character server type that is created during the conversion, irrespective of whether it is a variable length character (VARCHAR) or an LOB type ( VARCHAR(max)) because character strings of a larger size can also be converted during migration to CLOB data types.
|
|
_MSSBLANKDEFAULT
|
This variable translates an OpenEdge null string value("") to a server string with a single blank character(" ").
Note: This environment variable causes a null string ("") to convert to a single-space string (" ") on the server regardless of whether the Include Defaults option is set to ON or OFF during migration. This environment variable is used to enable the MSS DataServer migration to emulate the way an Oracle DataServer migration handles the conversion of null strings. This provides for an application, whose queries depend upon the character field containing a single-space string by default, to behave the same way in MSS as it does in Oracle. The purpose of this environment variable is to provide data compatibility between MSS and Oracle for character default values.
|
|
Environment variable
|
Interface element
|
Description
|
|
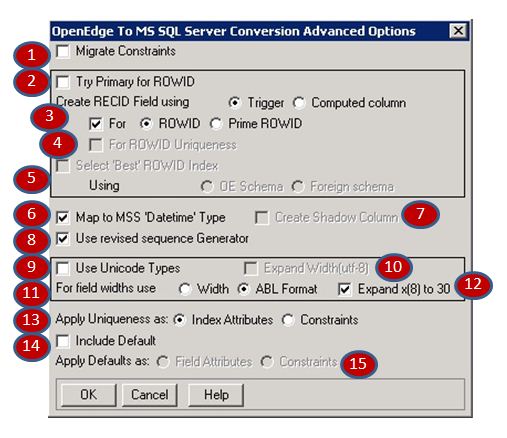
MIGRATECONSTR
|
Migrate Constraints
|
Default: NO
Set to YES to migrate constraint definitions from the OpenEdge database definitions to real constraint objects in the foreign data source and constraint definitions in the schema image.
|
|
MAPOEPRIMARY
|
Try Primary for ROWID
|
Default: NO
Determines if the OpenEdge primary should attempt to map itself to the SQL Server primary constraint and/or clustered index and/or the DataServer ROWID.
Dependencies: If MIGRATECONSTR is set to YES, this option is superseded in the conversion process by existing constraints in determining the DataServer ROWID.
|
|
COMPATIBLE
|
Create RECID Field using:
|
Default: Yes or 1
Determines if the migration must generate table definitions that provide compatibility with OpenEdge ROWID, RECID and with OpenEdge extent fields. When COMPATIBLE is set to NO, extent fields are not migrated, and array fields in OpenEdge databases are properly migrated to the server so that references to extend data types are properly mapped to the foreign data source and are handled the same as OpenEdge handles extents in the ABL.
When COMPATIBLE and GENROWID are both set to NO, PROGRESS_RECID is not generated to support OpenEdge ROWID and RECID and a version of the Select 'Best' ROWID Index algorithm is instead used to try to find existing indexes to support ROWID. For the Select 'Best' ROWID Index algorithm to support RECID in a backward compatible way, COMPATIBLE, GENROWID, MIGRATECONSTR, MAPOEPRIMARY and GENUNIQROWID options must all be unset. If any of these ROWID options are set in the conversion, the Select 'Best' ROWID Index algorithm will try to produce an index to support ROWID but that index may or may not support RECID.
When COMPATIBLE= 1 or Yes, it uses the legacy trigger behavior on the server to support PROGRESS_RECID.
When COMPATIBLE= 2, it uses the computed column approach to supporting PROGRESS_RECID on the server.
Dependencies:
Toggling the COMPATIBLE value on or off was equivalent to toggling the Create RECID Field option on or off in MS SQL Server DataServer versions prior to OpenEdge 11.
Beginning in OpenEdge 11.1, the legacy COMPATIBLE option is extended by GENROWID, MIGRATECONSTR, MAPOEPRIMARY and GENUNIQROWID options that are used to generate OpenEdge-compatible ROWID solutions that may or many not be compatible with OpenEdge RECID.
The GENROWID option is active by default so that the migration does take advantage of the new ROWID features (that are not backward-compatible) by default. Explicitly unset GENROWID and all other ROWID options (GENROWID, MIGRATECONSTR, MAPOEPRIMARY and MAPOEPRIMARY) if you want backward compatible behavior.
For a detailed explanation of how COMPATIBLE and GENROWID options work together, see the NOTE section at the end of the table.
|
|
GENROWID
|
Create RECID Field using:
For:
|
Default: Yes or 1
Determines if the migration must generate table definitions that provide compatibility with OpenEdge ROWID and RECID. When COMPATIBLE and GENROWID are both set to no, PROGRESS_RECID is not generated to support OpenEdge ROWID and RECID.
When GENROWID= 1 or Yes, it is the equivalent of COMPATIBLE= 1 or Yes with regard to support for OpenEdge ROWID and RECID; except that its value does not determine whether the trigger or computed column approaches should be used to support PROGRESS_RECID. Only COMPATIBLE determines that behavior.
When GENROWID= 2, it is equivalent to setting GENROWID=1 except that when the PROGRESS_RECID index is created on the server and designated as the ROWID/RECID selection, it also creates a primary constraint over PROGRESS_RECID index key.
Dependencies:
Starting in OpenEdge 11.0 when GENROWID=NO, a new algorithm for GETBESTROWID is used by default. When GETBESTROWID=YES, it is mutually exclusive with the ROWID/RECID selection activities of both COMPATIBLE and GENROWID. But, the GETBESTROWID algorithm gets turned on and off like a toggle switch when COMPATIBLE is used for ROWID/RECID selection.
Whereas, when the GETBESTROWID algorithm is on starting in OpenEdge 11.0, its operations can be complimentary to other ROWID options available starting in OpenEdge 11.0. Also, the existing index selected by the GETBESTROWID algorithm for ROWID starting in OpenEdge 11.0 may or may not be compatible with OpenEdge RECID functionality. Only when the ROWID index selected by the algorithm is a single component integer or Big integer key is it also compatible with RECID.
For a detailed explanation of how COMPATIBLE and GENROWID options work together, see the NOTE section at the end of the table.
|
|
GENUNIQROWID
|
Create RECID Field using:
|
Default: NO
Generates the PROGRESS_RECID_UNIQUE column for tables whose primary and/or clustered index selection does not qualify for ROWID designation because it is not unique. This option appends PROGRESS_RECID_UNIQUE to the end of the existing index component so that uniqueness and OpenEdge ROWID support can be obtained through that index.
As there are potential performance benefits to finding and assigning the most appropriate ROWID candidate for OpenEdge as ROWID, adding uniqueness to non-unique indexes increases the ROWID eligibility of that key and the potential that the ROWID designation will benefit from both MS SQL Server and DataServer performance.
When GENUNIQROWID=YES, non-unique indexes are considered for ROWID designation but none of the non-unique indexes is actually appended with a unique component unless the ROWID selection algorithm actually selects that non-unique index for ROWID designation. Only a non-unique index that is designated for ROWID is actually appended with a component that supplies uniqueness to the index.
Dependencies: If you set the option, GENROWID to Yes, 1 or 2, then the system ignores the setting. The PROGRESS_RECID_UNIQUE column can make non-unique keys eligible for ROWID and can be used in combination with three other options that are used during migration to seek ROWID eligibility from indexes or constraints. If GENUNIQROWID is set to YES in conjunction with either the MIGRATE_CONSTR, MAPOEPRIMARY or GETBESTFORROWID ROWID options, then all non-unique indexes are considered for PROGRESS_RECID_UNIQUE supplementation when tying to establish index eligibility for ROWID key designation.
Note: For detailed explanation of how GENROWID, GETUNIQROWID and COMPATIBLE options work together, see the note section at the end of the table.
|
|
GETBESTROWID
|
Select 'Best' ROWID Index using:
|
Default: NO
Looks at existing indexes over the table and tries to identify the "Best" ROWID candidate based on index uniqueness, data types, number of components, and mandatory component characteristics.
Dependencies: Select 'best' ROWID index is mutually exclusive to the GENROWID and COMPATIBLE options. So, when GETBESTROWID is set to YES, COMPATIBLE, and GENROWID must be set to NO. However, one of the following should be true at all times:
|
|
MAPMSSDATETIME
|
Map to MSS 'Datetime' type
|
Default: Yes
Specifies whether DATE and DATETIME data types in OpenEdge must map to legacy DATETIME timestamp data types in MSS Server.
If set to Yes, it provides backward-compatibility to earlier version of OpenEdge and MSS Server. However, if your database target is MSS 2008 or above and MAPSMSSDATETIME is set to No, more accurate mapping takes place between OpenEdge data and time data types and the new data and time data types in MSS Server.
|
|
SHADOWCOL
|
Create Shadow Column
|
Default: NO
Determines if shadow columns must be added to the record layout to represent data in upper case form for OpenEdge fields marked case-insensitive.
Dependencies: If MSSCASESEN is set to YES, the SHADOWCOL value is ignored.
|
|
MSSREVSEQGEN
|
Use Generator
|
Default: NO
Determines if migration must use generator or the old sequence generator when migrating sequences to foreign data source. When MSSREVSEQGEN is set to NO, the legacy sequence generator is migrated instead of the revised version
.
|
|
MSSSEQ
|
Native Sequence Generator
|
Default: NO
Select to migrate OpenEdge Sequences to MS SQL sequences
|
|
SEQCACHESIZE
|
Cache Size
|
If the Try Native Sequence option is selected, then the Cache Size option is made available for entry. This determines the size of the cache that should be used on the server for the cache size. The following three values are applicable:
|
|
UNICODETYPES
|
Use Unicode Types
|
Default: NO
Maps OpenEdge character fields to MSS Server unicode data types.
Dependencies: Selecting this option changes the default code page to UTF-8 and directs the schema migration to convert all character and CLOB data types in the OpenEdge database to Unicode data types on the server.
|
|
UNICODE_EXPAND
|
Expand Width (utf-8)
|
Default: NO
Set to YES to double the length of fields on conversion, and NO otherwise.
If set to YES, the single-byte characters receive adequate size as double-byte characters in MSS UCS-2 format.
|
|
SQLWIDTH
|
For field widths use:
|
Default: NO
Specifies if the migration must use the _WIDTH field to calculate column size instead of using the format field.
Dependencies: Specify YES to use the _width field in the column's schema image to calculate column size in place of the default format field, else ABL Format is used to size migrated column.
|
|
EXPANDX8
|
Expand x(8) to 30
|
Default: Yes
Determines whether character fields set to the default format size of x(8) should be expanded to a 30 character default. This expands the default length on the foreign data source.
Dependencies: The option only affects the batch conversion if SQLWIDTH is set to NO, which utilizes 4GL Format for character size translation to the foreign data source. If SQLWIDTH is set to YES, this option is ignored.
|
|
UNIQUECONSTR
|
Apply Uniqueness as:
|
Default: NO
Specify YES to create named Unique constraints for index uniqueness, otherwise retain the default of automatically using Index attributes to define index uniqueness for unique indexes migrated from an OpenEdge database.
|
|
CRTDEFAULT
|
Include Default
|
Default: NO
Specify YES to include OpenEdge initial values in the schema image definitions of the foreign data source in the schema holder database with fields migrated to columns in the foreign data source.
When CRTDEFAULT is off, the initial values are assigned out of the schema image to records created in the foreign data source by the OpenEdge DataServer.
When CRTDEFAULT is YES, the initial values are actually transferred and become part of the server definitions, not just the schema image definitions.
|
|
DFLTCONSTR
|
Apply Defaults as:
|
Default: NO
Specify YES to create named default constraints for initial values rather than setting the DEFAULT column attribute of the generated server column.
Dependencies: If the OpenEdge initial value is going to be migrated to the foreign data source, CRTDEFAULT must be set to YES.
|

|
PRODBNAME=db-name; export PRODBNAME
PROCONPARMS="-1 -i" SHDBNAME=schema-holder-name; export SHDBNAME . . . pro -b -p prodict/mss/protomss.p |