Data blocks are the most common blocks in the database. There are two types of data blocks: RM blocks and RM chain blocks. The only difference between the two is that RM blocks are considered full and RM chain blocks are not full. The internal structure of the blocks is the same. Both types of RM blocks are social. Social blocks can contain records from different tables. In other words, RM blocks allow table information (records) from multiple tables to be stored in a single block. In contrast, index blocks only contain index data from one index in a single table.
The number of records that can be stored per block is tunable per storage area. See the Data layout for a discussion of calculating optimal records per block settings.
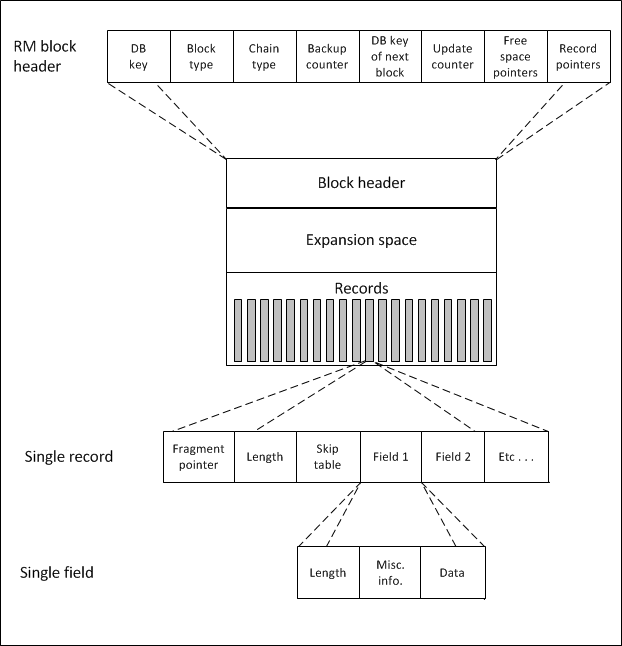
Each RM block contains four types of information:
Block header
Records
Fields
Free space
The block header contains the address of the block (dbkey), the block type, the chain type, a backup counter, the address of the next block, an update counter (used for schema changes), free space pointers, and record pointers. For a Type I storage area, the block header is 16 bytes in length. For a Type II storage area, the block header is variable; the header of the first and last block in a cluster is 80 bytes, while the header for the remaining blocks in a cluster is 64 bytes. Each record contains a fragment pointer (used by record pointers in individual fields), the Length of the Record field, and the Skip Table field (used to increase field search performance). Each field needs a minimum of 15 bytes for overhead storage and contains a Length field, a Miscellaneous Information field, and data.
The following figure shows the layout of an RM block.