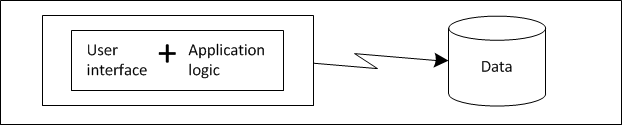
Traditional client/server development is based on a logical and physical two-tier computing model. It is deployed across two machines and connected through a network. The user interface and application logic are tightly integrated and located on a client machine, while the data resides on a separate server machine.
The following figure shows this two-tier configuration. Often, the client application runs on a limited desktop machine; the real computing power is reserved for moving data on the server.
Figure 1. Traditional two-tier model
Although applications based on this model are relatively easy to build, they are generally limited in size and computing power and tend to rely on a great deal of custom code. These limitations can:
Restrict the possibility of increased performance because all data required for the application logic is also passed to the same machine that manages the user interface. Thus, user interface response can suffer while waiting for application logic to process the data coming over the network.
Reduce maintainability by allowing enhancements to propagate changes throughout the application code.
Reduce data security because the user interface is essentially one with the application logic that handles the data.
Make integration difficult because the higher volume of custom code and often-specialized data formats prevent any convenient interface with other application domains, perhaps similarly limited.
Constrain any growth in access requirements because the application logic is tied to a single user interface instance.
Hinder re-use of common functions because the code must be duplicated on each machine that hosts the application.