This section discusses more precisely what record buffers do for you.
Whenever you reference a database table in a procedure and the ABL Virtual Machine (AVM) makes a record from that table available for your use, you are using a record buffer. The AVM defines a record buffer for your procedure for each table you reference in a FIND statement, a FOR EACH block, a REPEAT FOR block, or a DO FOR block. The record buffer, by default, has the same name as the database table. This is why, when you use these default record buffers, you can think in terms of accessing database records directly because the name of the buffer is the name of the table the record comes from. Think of the record buffer as a temporary storage area in memory where the AVM manages records as they pass between the database and the statements in your procedures.
You can also define your own record buffers explicitly, though, using this syntax:
Syntax
DEFINE BUFFER <buffer-name> FOR <table-name>.
There are many places in complex business logic where you need to have two or more different records from the same table available to your code at the same time, for comparison purposes. This is when you might use multiple different buffers with their own names. Here's one fairly simple example. In the following procedure, which could be used as part of a cleanup effort for the Customer table, you need to see if there are any pairs of Customers in the same city in the US with zip codes that do not match.
Here is the code that gives you these records:
DEFINE BUFFER Customer FOR Customer.
DEFINE BUFFER OtherCust FOR Customer.
FOR EACH Customer NO-LOCK WHERE Customer.Country = "USA":
FIND FIRST OtherCust NO-LOCK
WHERE Customer.State = OtherCust.State
AND Customer.City = OtherCust.City
AND SUBSTRING(Customer.PostalCode, 1,3) NE
SUBSTRING(OtherCust.PostalCode, 1,3)
AND Customer.CustNum < OtherCust.CustNum NO-ERROR.
IF AVAILABLE OtherCust THEN
DISPLAY
Customer.CustNum
Customer.City FORMAT "x(12)"
Customer.State FORMAT "xx"
Customer.PostalCode
OtherCust.CustNum
OtherCust.PostalCode.
END.
Take a look through this procedure. First, there is a pair of buffer definitions for the Customer table, one called Customer and one called OtherCust. The first definition, DEFINE BUFFER Customer FOR Customer, might seem superfluous because you get a buffer definition automatically when you reference the table name in your procedure. However, there are reasons why it can be a good idea to make all of your buffer definitions explicit like this. First, if you have two explicit buffer definitions up front, it makes it clearer that the purpose of this procedure is to compare pairs of Customer records. You might want to use alternative names for both buffers, such as FirstCust and OtherCust, to make it clear what your procedure is doing. This procedure uses an explicitly defined buffer with the same name as the table just to show that you can do this.
In addition, defining buffers that are explicitly scoped to the current procedure can reduce the chance that your code somehow inherits a buffer definition from another procedure in the calling stack. The defaults that ABL provides can be useful, but in serious business logic being explicit about all your definitions can save you from unexpected errors when the defaults don't work as expected.
Next the code starts through the set of all Customers in the USA. For each of those Customers, it tries to find another Customer with the same City and State values:
FOR EACH Customer NO-LOCK WHERE Customer.Country = "USA":
FIND FIRST OtherCust NO-LOCK
WHERE Customer.State = OtherCust.State
AND Customer.City = OtherCust.City . . .
Because you need to compare one Customer with the other, you can't simply refer to both of them using the name Customer. This is the purpose of the second buffer definition. Because the code is dealing with two different buffers that contain all the same field names, you need to qualify every single field reference to identify which of the two records you're referring to.
The next part of the WHERE clause compares the two zip codes, which are stored in the PostalCode field:
AND SUBSTRING(Customer.PostalCode, 1,3) NE
SUBSTRING(OtherCust.PostalCode, 1,3) ...
This procedure assumes that the last two digits of a zip code can be different within a given city, but that the first three digits are always the same. Because the PostalCode field is used for codes outside the US, which are sometimes alphanumeric, it is a character field, so the SUBSTR function extracts the first three characters of each of the two codes and compares them. If they are not equal, then the condition is satisfied.
The last bit of the WHERE clause needs some special explanation:
...
AND Customer.CustNum < OtherCust.CustNum NO-ERROR.
As the code walks through all the Customers, it finds a record using the Customer buffer and another record using the OtherCust buffer that satisfy the criteria. But later it also finds the same pair of Customers in the opposite order. So to avoid returning each pair of Customers twice, the code returns only the pair where the first CustNum is less than the second.
The FIND of the second Customer with a zip code that doesn't match the first is done with the NO-ERROR qualifier, and then the DISPLAY is done only if that record is AVAILABLE:
IF AVAILABLE OtherCust THEN
DISPLAY
Customer.CustNum
Customer.City FORMAT "x(12)"
Customer.State FORMAT "xx"
Customer.PostalCode
OtherCust.CustNum
OtherCust.PostalCode.
In the DISPLAY statement you must qualify all the field names with the buffer name to tell the AVM which one you want to see. In the case of the City and State it doesn't matter, of course, because they're the same, but you still have to choose one to display.
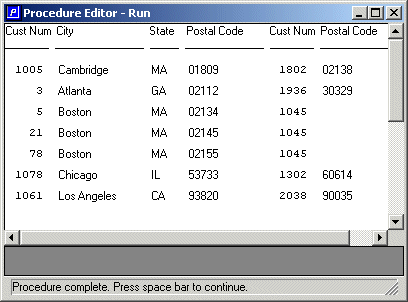
The following figure shows what you get when you run the procedure.
Figure 27. Comparing zip codes
You'll notice that the procedure takes a few seconds to run to completion. This is because the City field and the State field aren't indexed at all. For each of the over 1000 Customers in the USA, the procedure must do a FIND with a WHERE clause against all of the other Customers using these nonindexed fields. The PostalCode comparison doesn't help cut down the search either, because that's a nonequality match and the PostalCode is only a secondary component of an index. The code must work its way through all the Customers with higher Customer numbers looking for the first one that satisfies the selection. The fact that the OpenEdge database can do these many thousands of searches in just a few seconds is very impressive. There are various ways to make this search more efficient but they involve language constructs you haven't been introduced to yet, so this simple procedure serves for now.