The first and most obvious characteristic of queries is precisely that they are not block-oriented. The language statements you've used in the last few chapters are all tied to blocks of ABL code. You define a result set inside a block beginning with DO, FOR, or REPEAT. The result set is generally scoped to the block where it is defined. The term result set denotes the set of rows that satisfy a query.
You learned which of the block types iterate through the result set automatically and which require you to explicitly find the next record.
Even the FIND statement itself, although it does not define a block, is subject to the same rules of record scoping. You've learned how the presence of record-oriented blocks like a FOR EACH block and FIND statements together define the scope of a record buffer within a procedure.
These are among the most powerful features in ABL. They help give it its unique flexibility and strength for defining complex business logic in a way that ties data access statements closely to the logic that uses the data.
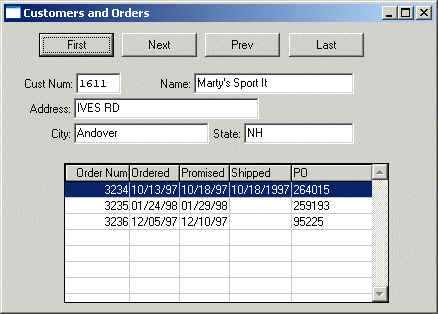
However, there are times when you don't want your data access tied to the nested blocks of ABL logic in your procedures. Earlier chapters briefly discussed the notion of event-driven applications. Think about the procedure h-CustOrderWin1.w, for instance. When you run this, a Customer and its Orders are displayed for you, as shown in the following figure.
Figure 36. Customers and Orders sample window
Iterating through the data, for example through all the Customers in New Hampshire, isn't done inside a block of ABL logic. It's done entirely under user control. Defining the Customer result set and its Order result set using queries is essential to this. When the user clicks the Next button, the code retrieves and displays the next record in the result set:
DO:
GET NEXT CustQuery.
IF AVAILABLE Customer THEN
DISPLAY Customer.CustNum Customer.Name Customer.Address Customer.City
Customer.State
WITH FRAME CustQuery IN WINDOW CustWin.
{&OPEN-BROWSERS-IN-QUERY-CustQuery}
END.
This happens independently of the block of code where the query is defined, or where it is opened. This gives you great flexibility as a developer to let user interface events, or other programmatic events, determine the flow of the application and the processing of data. By contrast, the examples you built in RecordBuffers and Record Scope were chunks of logic that executed independently of the user interface, such as in the procedure h-BinCheck.p, which does some calculations and returns the results to another procedure.
This is the essence of the difference between queries and block-oriented data access. You use queries when you need to keep the data access separate from the structure of the procedure, and instead control it by events. You use block-oriented data access when you need to define business logic for data within a defined scope.
Thus queries give your data access language these important characteristics:
Scope independence — You can refer to the records in the query anywhere in your procedure.
Block independence — You are not required to do all your data access within a given block.
Record retrieval independence — You can move through the result set under complete control of either program logic or user events.
Repositioning flexibility — You can position to any record in the result set at any time.