APWs are optional and require an Enterprise database license. APWs are highly recommended because they improve performance in the following ways:
They ensure that a supply of empty buffers is available so the database engine does not have to wait for database buffers to be written to disk.
They reduce the number of buffers that the engine must examine before writing a modified database buffer to disk. To keep the most active buffers in memory, the engine writes the least recently used buffers to disk; the engine must search buffers to determine which one is least recently used.
They reduce overhead associated with checkpointing because fewer modified buffers have to be written to disk when a checkpoint occurs.
You must manually start APWs. You can start and stop APWs at any time without shutting down the database. See StartingUp and Shutting Down for instructions on starting and stopping an APW.
A database can have zero, one, or more APWs running simultaneously. The optimal number is highly dependent on your application and environment. Start two APWs and monitor their performance with PROMON. If there are buffers being flushed at checkpoints, add an additional APW and recheck. Applications that perform fewer changes to a database require fewer APWs.
Note: If you do not perform any updates, no page writers are required.
APWs are self-tuning. Once you determine how many APWs to run, you do not have to adjust any startup parameters specific to APWs. However, you might want to increase the BI cluster size to allow them to perform at an optimal rate. PROUTIL TRUNCATE BI lets you create a BI cluster of a specific size. For more information, see PROUTILTRUNCATE BI qualifier.
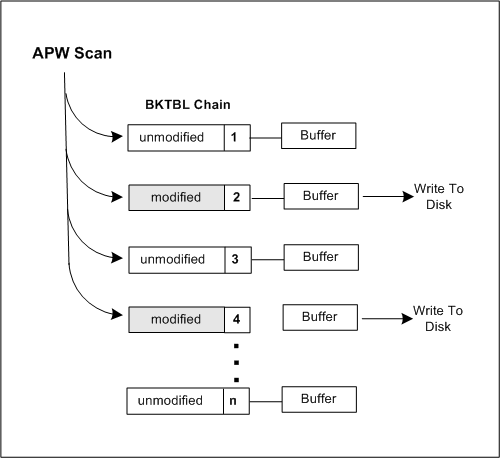
APWs continually write modified buffers to disk, making it more likely the server will find an unmodified buffer without having to wait. To find modified buffers, an APW scans the Block Table (BKTBL) chain. The BKTBL chain is a linked list of BKTBL structures, each associated with a database buffer. Each BKTBL structure contains a flag indicating whether the associated buffer is modified. When an APW finds a modified buffer, it immediately writes the buffer to disk.
The following figure illustrates how an APW scans the BLKTBL chain.
Figure 33. Block Table (BLKTBL) chain
The APW scans in cycles. After completing a cycle, the APW goes to sleep. When the APW begins its next scanning cycle, it picks up where it left off. For example, if the APW scanned buffers 1 to 10 during its first cycle, it would start at buffer 11 to begin its next cycle.
When the database engine writes modified buffers to disk, it replaces the buffers in a least-to-most-recently-used order. This is beneficial because you are less likely to need older data.
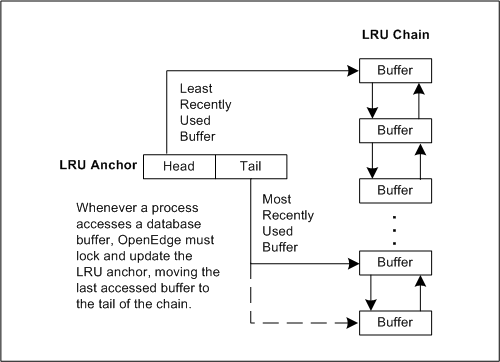
To find least recently used buffers, an APW scans the least recently used (LRU) chain. The least recently used chain is a doubly linked list in shared memory that the engine uses to access database buffers. The LRU chain is anchored by a data structure that points to the head and tail of the chain. Whenever a process accesses a database buffer, the server must lock and update the LRU anchor, moving the accessed buffer to the tail of the chain.
The following figure illustrates the LRU chain.
Figure 34. APWs and the least recently used chain
Since all processes must lock the LRU anchor whenever they have to access a buffer, long buffer replacement searches create contention for all processes accessing the database buffer pool. This can have a debilitating effect on performance, especially on heavily loaded systems. APWs reduce contention for the LRU anchor by periodically clearing out modified buffers. When buffer replacement is required, the database engine can find an unmodified buffer quickly.
A third way that APWs improve performance is by minimizing the overhead associated with before-image checkpointing.
The before-image file is divided into clusters. A checkpoint occurs when a BI cluster becomes full. When a cluster becomes full, the database engine reuses the cluster if the information stored in it is no longer required. By reusing clusters, the engine minimizes the amount of disk space required for the BI file.
Checkpoints ensure that clusters can be reused and that the database can be recovered in a reasonable amount of time. During a checkpoint, the engine writes all modified database buffers associated with the current cluster to disk. This is a substantial overhead, especially if you have large BI clusters and a large buffer pool. APWs minimize this overhead by periodically writing modified buffers to disk. When a checkpoint occurs, fewer buffers must be written.