Corticon's Advanced Data Callout (ADC) provides an alternative to Corticon’s Enterprise Data Connector (EDC) for accessing database data. It provides greater control over the query, and insert statements that are used. This is beneficial when you need finer control for performance or need to retrieve large amounts of data. Batch processing applications are a good example of where ADC is effective. With ADC you define a mapping of your vocabulary to a database, define queries, and control when queries are performed to retrieve data. With ADC you can quickly retrieve large amounts of data.
By contrast, with EDC you define a mapping of your vocabulary to a database and rely on Corticon to retrieve data as needed. EDC makes data access very simple and is a great option when small amounts of data are needed or performance is not paramount. EDC performs lazy loading of data in that it only loads data as needed. This is particularly evident when retrieving data for associations. When large amounts of data need to be retrieved or performance is paramount this can be inefficient.
Comparing ADC and EDC
Consider a database with tables and relations such as:
‘Person’ Table has 1,000 rows
‘Job’ Table has 10,000 rows (10 associated Job records for each Person record)
‘Duty’ Table has 100,000 rows (10 associated Duty records for each Job)
In EDC, you create one SQL Statement to retrieve all Person Entities into Corticon, and then one SQL Statement is created for each Person to load that Person’s associated Job Entities – another 1,000 SQL executions. Then, with one SQL Statement for each Job to load that Job’s associated Duty Entities adds another 10,000 SQL executions to the process. A lot of time is dedicated to retrieving data. With ADC this can be reduced to three queries; one for each table. This can greatly reduce the time spent accessing data.
How ADC Works
ADC functions as a service callout -- it accesses data as a step in a Ruleflow. To use ADC, do the following:
1. Map your vocabulary to a database. This is done in Corticon vocabulary editor the same as is done for EDC. The mapping tells ADC how to construct entities and associations for data retrieved from the database and how to save data when storing to the database.
2. Define parameterized SQL statements for the queries and to be performed. You have full control over these queries. They are parameterized such that substitutions can be performed at runtime. To make these statements easy to manage, they are also stored in a database. This can the same or separate database from the data to be queried.
3. Add the ADC callout to a Ruleflow. This is done in the Corticon Ruleflow editor. When you add ADC to a Ruleflow you will need to configure it to identify the query or insert operation to be performed by selecting one of the SQL statements you have defined. To make this easier, you can give the SQL statements logical names.
When all steps are completed you are ready to deploy your Ruleflow or test it in the Corticon tester. When ADC runs it will perform substitutions into the statement and use it to access data. For queries, ADC will construct entities, set attributes, and define associations using the vocabulary mapping. For inserts, ADC will use the mapping data for storing to the database. You can use multiple instance of ADC in a Ruleflow. A typical use case would be to have an instance at the start of a Ruleflow to retrieve data and one later in the Ruleflow to save data.
Configuration of the ADC Database Schema
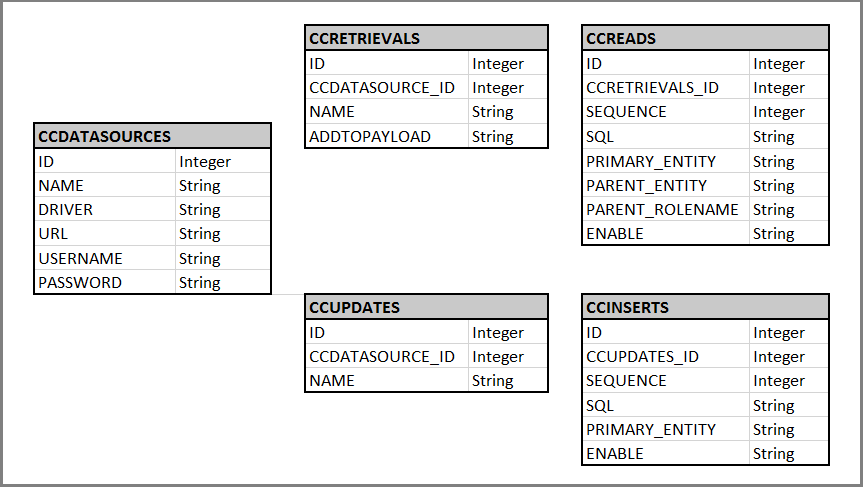
The following diagram illustrates the Database Schema that ADC uses. SQL Scripts help you generate these Tables inside your Database. However, the Table and Column names cannot be changed because the ADC is hardcoded to look for specific names.
Figure 273. Database Schema for Corticon's Advanced Data Access Service Callout
The core operations that an ADC can perform are: retrieving data (using the CCRETRIEVALS Table) and updating data (using the CCUPDATES Table). Each one of these CCRETRIEVALS or CCUPDATES row instances can use a different DataSource (using the CCDATASOURCES Table). Because there is a Foreign Key from CCRETRIEVALS and CCUPDATES back to CCDATASOURCES (CCDATASOURCES_ID), each CCRETRIEVALS and CCUPDATES can only connect to one CCDATASOURCES.
Table 23. CCDATASOURCES Table
Column Name : DataType
Note
ID : Integer
The Primary Key for the Table which then gets propagated down to each CCRETRIEVALS or CCUPDATES record.
NAME : String
A logical name that you want to associated with this DataSource. This name can be used in to lookup an already established Connection through a JNDI call. If the JNDI Lookup fails, then the new Connection is stored in memory, using this name, to be reused by other execution Threads.
DRIVER : String
The Driver Class that will be used to make the Connection to the Database. This value has two different meanings 1) Progress’ DataDirect Driver ID or 2) Third Party Driver Class. It is strongly recommended that the customer sets the DataDirect Driver ID, instead of a Third Party Class. Supported Databases with the associated DataDirect ID are:
Database Id | Database Name ==================================================================== com.corticon.database.id.Oracle12c | Oracle Database 12c com.corticon.database.id.Oracle10g | Oracle Database 10g com.corticon.database.id.Oracle | Oracle Database 11g com.corticon.database.id.DB210.5 | IBM DB2 10.5 com.corticon.database.id.DB2 | IBM DB2 9.5 com.corticon.database.id.MsSql | Microsoft SQL Server 2008 com.corticon.database.id.MsSql2012 | Microsoft SQL Server 2012 com.corticon.database.id.MsSql2014 | Microsoft SQL Server 2014 com.corticon.database.id.MySQL | MySQL 5.6 Database com.corticon.database.id.PostgreSQL| PostgreSQL 9.4 Database com.corticon.database.id.OE11.5 | Progress OpenEdge 11.5 com.corticon.database.id.OE11.4 | Progress OpenEdge 11.4 com.corticon.database.id.OE11.3 | Progress OpenEdge 11.3 com.corticon.database.id.OE10.2 | Progress OpenEdge 10.2
URL : String
URL to be used to connect to selected Database.
USERNAME : String
Username to authenticate on the selectetd Database.
PASSWORD : String
Password of the specified usernamme.
Table 24. CCRETRIEVALS Table
Column Name : DataType
Note
ID : Integer
The Primary Key for the Table which then gets propagated down to each CCREADS record.
CCDATASOURCE_ID : Integer
Foreign Key back to CCDATASOURCES.ID column. Each CCRETRIEVALS row can only have one associated CCDATASOURCES configuration.
NAME : String
A logical name that you want to associated with this CCRETRIEVALS. This is important because this is the name that will be specified inside of each ADC to determine which CCRETRIEVALS the ADC will perform.
ADDTOPAYLOAD : String (true or false)
Depending on your Use Case, you may not want the huge amounts of data retrieved from the ADC to be added to the Payload. Depending on how much data is retrieved, adding this data to an XML or JSONObject Payload could be costly. We parameterized this option per CCRETRIEVALS because maybe some retrieval data you want in the returned Payload and some you don’t.
If value is null, or any value other than ‘true’, the default is ‘false’.
Table 25. CCUPDATES Table
This Table is very similar to the CCRETRIEVALS Table.
Column Name : DataType
Note
ID : Integer
The Primary Key for the Table which then gets propagated down to each CCINSERTS record.
CCDATASOURCE_ID : Integer
Foreign Key back to CCDATASOURCES.ID column. Each CCUPDATES row can only have one associated CCDATASOURCES configuration.
NAME : String
A logical name that you want to associated with this CCUPDATES. Just like the CcRetrievalsName in the Ruleflow Properties Section, there is a CcUpdatesName that will be used to specify which CCUPDATES Name the ADC will perform.
Table 26. CCREADS Table
The CCREADS and CCINSERTS Tables are the key Tables for ADC. These Tables contain the most pertinent information for the ACA SCO to perform its duties.
Column Name : DataType
Note
ID : Integer
The Primary Key for the Table.
CCRETRIEVALS_ID : Integer (required)
Foreign Key back to CCRETRIEVALS.ID column. There can be many CCREADS associated with a CCRETRIEVALS record.
SEQUENCE : Integer (required)
Because there can be multiple CCREADS associated with a CCRETRIEVALS record, we need to know what order to execute the CCREADS. The ADC will read in all the CCREADS into memory, and then sort them based on the value for SEQUENCE. Ideally, the values will be sequential, but since there is not Database Constraint on this Column, the values don’t have to be sequential (1,4,6,7) or even unique. However, if the numbers are not unique (1,4,4,7), the CCREADS may fire in different orders per execution.
SQL : String (required)
An SQL Statement that is technically a template that will be used for this CCREADS operation. The SQL Statement is very flexible in that it can incorporate complex WHERE clause using Corticon’s Variable Substitution. Variable Substitution allows you to specify Entity.Attribute keys in the SQL, which will be replaced with corresponding values based on what is currently in the working memory of the execution. This is explained in more detail later in this document.
PRIMARY_ENTITY : String (required)
The results from the SQL Statement. This needs to be converted to map to Corticon Entities. This field is to tell the ADC which Entity to map the results.
The ADC will not automatically “create” a new instance of the Entity in memory. First, it will determine if that Entity is already in memory, and if it is not already in memory, a new Entity instance of type (PRIMARY_ENTITY) will be created, using ICcDataObjectManager.createEntity(<PRIMARY_ENTITY>). Then the Column Values for that Row will be added into that new instance of the Entity.
Things get more complicated when there are already instances of the <PRIMARY_ENTITY> as the Entity that is in working memory. To prevent duplication of Entity instances, we want to first check to see if that Entity instance is already in memory. If we determine that the instance already exists, then we will use that instance, and then merge the Column Values into that Entity instance.
An example of this is covered in section “Root Entity with no Variable Substitution : Example 2” below.
PARENT_ENTITY : String and PARENT_ROLENAME : String (optional)
These values are needed to create an Association between the Parent Entity (PARENT_ENTITY) to the Target Entity (PRIMARY_ENTITY) through Association Role Name (PARENT_ROLENAME).
This is the most complicated part of ADA SCO.
The Association’s Role Name: Join Expression is critical to the mapping of Associations between the PARENT_ENTITY and the PRIMARY_ENTITY.
The ADC parses the Join Expression to determine which Attributes in the Parent Entity need to match which Attributes in the Primary Entity. For each Primary Entity retrieved, an extensive algorithm is used to match these values between two different Entities. If there is a match, the Primary Entity is added to the Parent Entity’s Association Role Name.
ENABLE : String (true or false)
For testing purposes, you may want to test some CCREADS out of all the ones associated with the CCRETRIEVALS. You can add all your CCREADS information and then incrementally expand the retrieval, while testing each step.
If value is null, or any value other than ‘false’, the default is ‘true’.
Table 27. CCINSERTS Table
The CCREADS and CCINSERTS Tables are the key Tables for ADC. These Tables contain the most pertinent information for the ADC to perform its duties.
Column Name : DataType
Note
ID : Integer
The Primary Key for the Table
CCUPDATES_ID : Integer
Foreign Key back to CCUPDATES.ID column. Because of this, there can be many CCINSERTS associated with a CCUPDATES record.
SEQUENCE : Integer
Because there can be multiple CCINSERTS associated with a CCRETRIEVALS record, we need to know what order to execute the CCINSERTS. The ADC will read in all the CCINSERTS into memory, and then sort them based on the value for SEQUENCE. Ideally, the values will be sequential, but since there is not Database Constraint on this Column, the values don’t have to be sequential (1,4,6,7) or even unique. However, if the numbers are not unique (1,4,4,7), the CCINSERTS may fire in different orders per execution.
SQL : String
SQL Statement used as a template for this CCINSERTS operation. The SQL Statement is very flexible and uses Variable Substitution to add Primary Entity values directly into the SQL.
Since the structure of an INSERT statement is drastically different than a SELECT statement, Variable Substitution will not aggregate all values to create one SQL statement, but instead, it will use the SQL as a template to create a SQL statement for each Primary Entity instance.
PRIMARY_ENTITY : String
The Entity name that will be used to look up all instances of this Entity type from working memory in which Variable Substitution will be applied to the SQL statement to create an individual INSERT statement per Entity instance.
ENABLE : String (true or false)
For testing purposes, you may want to test some CCINSERTS out of all the ones associated with the CCUPDATES. You can add all your CCINSERTS information and then incrementally expand the updates, while testing each step. If value is null, or any value other than ‘false’, the default is ‘true’.
Configuration of the ADC Database Metadata
As described in the schema, CCDATASOURCES are defined in the database that is retrieved by the ADA SCO as Metadata stored in the CcADASco.properties file in the [CORTICON_WORK] directory.
Storing Configuration Metadata in a database provides flexibility and security. The Metadata could be saved into the same database as core customer data, or different database. The ADC looks up metadata to perform its current operation.
Table 28. CcADASco.properties File
This file requires a value for each of the following properties:
Property Name
Property Values
corticon.servicecallout.lookup.name
The logical name for this Connection’s DataSource. This name first looks up a DataSource through a JNDI InitialContext. If no DataSource has been registered, then the following properties establish a Connection DataSource. Then, this DataSource is stored in memory, using its name so that other execution Threads can use the same DataSource.
corticon.servicecallout.lookup.drive
As described for CCDATASOURCES, this value can be the DataDirect Driver ID or the third party driver name.
corticon.servicecallout.lookup.url
Standard connection URL to the database.
corticon.servicecallout.lookup.username
The user to be authenticated on the database. You can choose to encrypt the username.
If there is a problem retrieving the metadata from the Database, Exceptions are logged into the Corticon Log file. If there is a problem during Runtime, a CcRuleMessages -> Violation message is posted and added to the Response.
Encrypting database credentials defined in the CcADASco.properties File
Corticon uses a proprietary encryption algorithm which is the recommended technique for encrypting credentials, as follows:
1. In a Corticon Server installation, open a Command Window at [CORTICON_HOME]\Server\bin\.
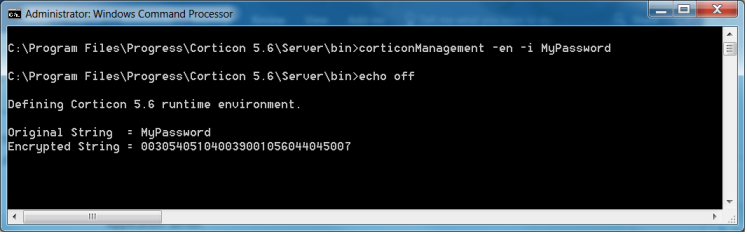
2. Type corticonManagement -en -i username. An encrypted String for the username you entered is output.
3. Copy the encrypted String to the appropriate CcADASco.properties file, and enter it as the value for corticon.servicecallout.lookup.username.
4. Type corticonManagement -en -i password. An encrypted String for the password you entered is output, as shown:
5. Copy the encrypted String to the appropriate CcADASco.properties file, and enter it as the value for corticon.servicecallout.lookup.password.
Associating a CcRetrievalsName or CcUpdatesName to a SCO
An ADC Runtime Properties on a Ruleflow canvas expects you to specify the property as either:
CcRetrievalsName for retrievals of the name value specified
CcUpdatesName for updates of the name value specified
For example:
Once you add the SCO to the Ruleflow, you can access to the Properties -> Runtime Properties section (shown in green). The value for CcRetrievalsName here is RETRIEVE_ABCD, the NAME of a CCRETRIEVALS Record in the Database (shown inpurple):
Efficient retrieval of large amounts of data
The SCO uses the metadata in CCDATASOURCES, CCRETRIEVALS, and CCREADS tables to query Database Tables so that they retrieve large amounts of data to be added to the working memory of the execution.
SCO Service Name = CcDatabaseServiceCallout.retrieveEntitiesFromDatabase
The core retrieval of data is based on what metadata is in the CCREADS table. This section describes how the SEQUENCE, SQL, PRIMARY_NAME, PARENT_NAME, and PARENT_ROLENAME are used in CCREADS records to retrieve large amounts of data.
There are four types of retrievals that can be configured:
1. Root Entity with no Variable Substitution
2. Associated Entities with no Variable Substitution
3. Root Entity with Variable Substitution
4. Associated Entities with Variable Substitution
Root Entity with no Variable Substitution
This type of retrieval utilizes the SQL and PRIMARY_NAME values inside the Database Row. The SQL retrieves rows from a Database Table and the results are mapped to what is defined in the PRIMARY_NAME.
Example 1:
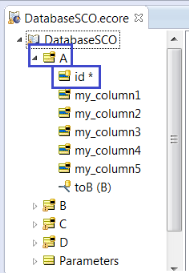
SQL = Select * from M_A PRIMARY_NAME = A
The SQL Statement retrieves all records from the M_A Table. A new Vocabulary A Entity instance (based on PRIMARY_NAME) is created for each row, and the contents of the row are added to the A instance.
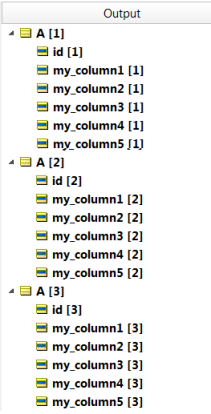
If there are three M_A records in the Database, the result from this retrieval is three A instances added to the working memory of the execution, as illustrated:
Note: All Entities and Attributes are in BOLD face (inside the Tester) -- that indicates that these Entities and Attributes were not part of the original payload.
Example 2:
As stated in the CCREADS > PRIMARY_ENTITY description, the ADC will not unconditionally create a new PRIMARY_ENTITY instance for every row that is retrieved. The SCO first checks to see if that instance is already in memory by comparing the working memory PRIMARY_ENTITY’s Identity Attribute(s) and comparing those values with the corresponding values from the retrieved record. If there is a match, then the working memory instance is used, and all the Data retrieved from the Database will override what is currently in the working memory instance.
SQL = Select * from M_A PRIMARY_NAME = A
The payload passed in, which gets added to working memory, is:
The output is:
A new instance A[2] and A[3] were created with the values from the Database.
However, A[1] -> id = 1 was already in memory along with default values of 999 for each of the column values. Based on Entity A’s Identity (defined in the Vocabulary), the system determined to reuse instance A[1] -> id = 1, and then merge the values from the Database.
There is hint here: A.id is not BOLD in the Output column of the tester. That means this Entity.Attribute didn’t change in Rule Processing. If it didn’t change (or get added), then it was part of the payload. This tells you that the passed in A[1] Entity was reused. Also, if the system didn’t look up for existing Entity A.id=1 instances, then a second A would be created with id=1.
Associated Entities with no Variable Substitution
This type of retrieval utilizes the SQL, PRIMARY_NAME, PARENT_NAME, and PARENT_ROLENAME values in the Database Row. This retrieval retrieves data that will be added in Entity instances -- but further, those instances will be added to an Entity’s Association through an Association’s Rolename.
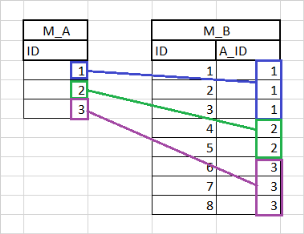
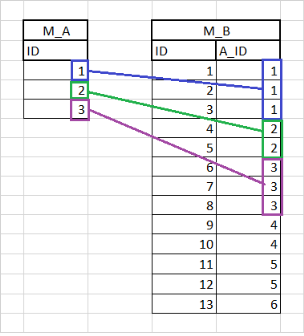
Example 1:
SQL = Select * from M_B PRIMARY_NAME = B PARENT_ENTITY = A PARENT_ROLENAME = toB
As described in the previous section, “Root Entity with no Variable Substitution”, the SQL and PRIMARY_NAME work together to create new instances or lookup an existing Entity instance in working memory, based on what is retrieved from the Database.
However, we don’t want to create a new PRIMARY_ENTITY instance if we know it won’t be associated to a PARENT_ENTITY. If the retrieved Database record won’t be added to an Association to any of the PARENT_ENTITYPRIMARY_ENTITY is valid and should be added to an A.toB Association, then it will be added.
The way that the ADC determines which B Entity is added to an individual A.toB Association is through the Vocabulary’s Association Join Statement. The Join Statements defines which Columns from each Table need to match for these two Entities to be associated with each other.
Using the existing example, the Association Join Statement defined for A.toB is:
M_A.ID = M_B.A_ID
Note: To avoid confusion, the Schema Name (which precedes the Table Name) has been removed, . The actual expression could be DATASYNC.M_A.ID = DATASYNC.M_B.A_ID, with DATASYNC the Schema Name associated with Tables M_A and M_B).
The record M_B is retrieved from the Database to first check whether the B record will be added to an Association, and then – if yes – create a new B record or lookup from working memory and reuse.
Assuming that M_B’s -> A_ID = 1 , the Join Expression is applied to find the A instance that has ID = 1.
If an A is found with ID=1, then the B instance will be added to that A’s toB Association.
If an A is not found with ID=1, then the B instance is ignored. It won’t be added to working memory and it won’t be associated with an A instance
Using the following data inside M_A and M_B...
… the following Associations between A and B will be created:
Note: The B Entity has a my_aid Attribute that maps to Database Column A_ID. This demonstrates that the Vocabulary Attribute Name doesn’t need to have the same name as the Column Name.
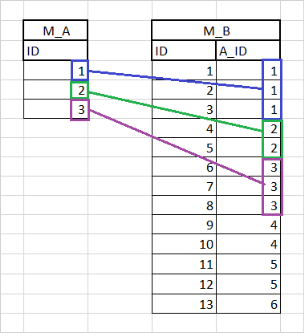
Example 2:
SQL = Select * from M_B PRIMARY_NAME = B PARENT_ENTITY = A PARENT_ROLENAME = toB
This example is very similar to Example 1, but there is additional data in this example's M_B Table.
Because the SQL is Select * from M_B, all 13 M_B records will be retrieved from the Database. However, records with ID = 9 to 13 don’t have a valid PARENT_ENTITY to associate with. In this case, those M_Bs will not be created, will not be added to working memory, and will not be associated with any PARENT_ENTITY (A instance).
The results from Example 1 will be the same as Example 2.
In this particular case, it is advised to have a more defined SQL Statement so that not all the M_B records are retrieved and then filtered inside the SCO. It is more efficient to create a dynamic WHERE clause using “Associated Entities with Variable Substitution”, discussed later in this section.
New SQL : Select * from M_B where a_id IN ({ A.id })
Using Variable Substitution, this new SQL would return only those M_B records with a_id values in the working set of A.id values. In the above case, the revised SQL would be dynamically changed to :
Select * from M_B where a_id IN (1, 2, 3)
Example 3:
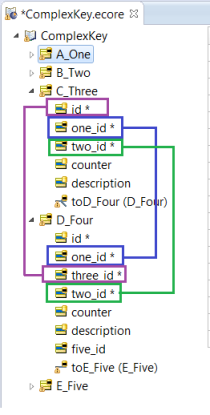
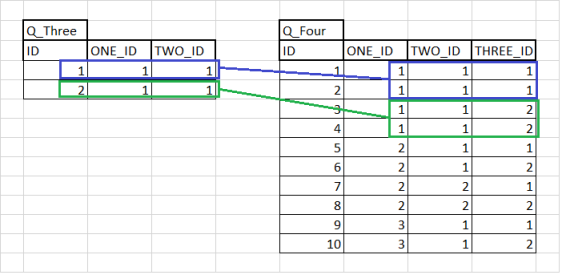
In the Example 1, the Join Expression linked two Entities based on only one Attribute. The next example shows that the ADC can handle more complex Join Expressions with multiple Attributes.
D_Four has an Identity of (id, one_id, two_id, and three_id).
As illustrated, D_Four has Foreign Keys back to C_Three Entity for Attributes one_id, two_id, and three_id. This will make the Join Expression much more complex.
As described in the previous section, “Root Entity with no Variable Substitution”, the SQL and PRIMARY_NAME work together -- based on what is retrieved from the Database -- to create new instances, or lookup an existing Entity instance in working memory. Now, take the newly created or looked up D_Four instance, find the correct C_Three instance, and then add the D_Four to C_Three.toD_Four Association.
With multiple Attributes part of the Join Expression, the ADC needs a little more processing comparing each Attribute value in the new D_Four instance to the Attribute values in C_Three.
Using the following data inside Q_Three and Q_Four:
The following Associations between C_Three and D_Four will be created:
Root Entity with Variable Substitution
Like the “Root Entity without Variable Substitution, this type of retrieval utilizes the SQL and PRIMARY_NAME values inside the Database Row. As before, The SQL will be used to retrieve rows from a Database Table and the results will be mapped to what is defined in the PRIMARY_NAME. However, Variable Substitution allows the SQL to be more complex by dynamically adding variable values to the WHERE clause of the SQL statement.
Example 1:
SQL = Select * from M_A where ID IN ( { A.id } ) PRIMARY_NAME = A
During execution of this CCREADS row, this SQL Statement will be processed as follows:
1. Read in the SQL and detect any Variable Substitutions have been added. In this case, there is a { A.id }. This A.id maps to the Vocabulary Entity=A and Attribute=id:
2. Query the working memory of the execution, and find all A Entities in memory, loop through each one,and then add each of A’s id values to a List. Assuming there are three A Entities in working memory, the List of values associated with A.id would be 1, 2, 3.
3. Use Variable Substitution to replace { A.id } with the list of values.
This produces a new SQL Statement: Select * from M_A where ID IN ( 1, 2, 3 )
This will be the actual SQL Statement that will be used by the CCREADS.
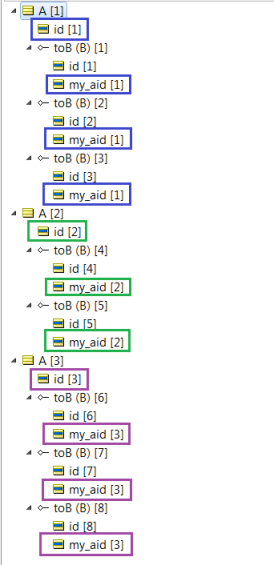
4. Because of the WHERE Clause limits where ID is in the set of (1, 2, 3), only three Rows will be returned from the Database. To prevent duplicate Entities in the working memory, the SCO will check to see if A:id=1, A:id=2, and A:id=3 are already in memory. For these Entities, they are reused and the data from the Database enhances each Entity by setting the my_column1, my_column2, my_column3, my_column4, and my_column5from the Database record, as illustrated:
In this case, A.id for each A instance was passed into the execution through the Payload, which is why its values are not BOLD in the illustration. This demonstrates that the system found an existing A instance with id=1, and reused it instead of creating a new A instance.
Example 2:
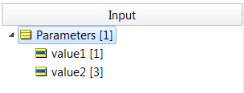
You are not limited to only one Variable Substitution per SQL. SQL can have any number of replacements, even from different Entities. In this example, Variable Substitution uses values from Entity Parameters.
SQL = Select * from A where ID > { Parameters.value1 } and ID < { Parameters.value2 } PRIMARY_NAME = A
Use the following input...
… in the form:
{Parameters.value1} = 1 {Parameters.value2} = 3 Updated SQL = Select * from M_A where ID > 1 and ID < 3
Since there is only one A Entity that satisfy the WHERE clause, then only one A Entity is returned from the Database and added to the working memory, as shown:.
Associated Entities with Variable Substitution
Like the “Associated Entities without Variable Substitution, this type of retrieval utilizes the SQL, PRIMARY_NAME, PARENT_NAME, and PARENT_ROLENAME values inside the Database Row. As before, the SQL will be used to retrieve rows from a Database Table and the results will be mapped to what is defined in the PRIMARY_NAME. These Entities will then be associated to the appropriate PARENT_ENTITY, through the PARENT_ENTITY’s PARENT_ROLENAME.
The difference in this scenario is that you can use Variable Substitution to better limit what is retrieved from the Database.
In Example #2 in “Associated Entities without Variable Substitution”, it was shown the by not using Variable Substitution, the SQL statement could retrieve extra rows that would not be added to the working memory.
The optimal use of Variable Substitution for Associated Entities is to try match the WHERE clause as closely as possible to the Foreign Key relationship between the two Tables. This relationship would also be expressed in the Vocabulary Association’s Join Expression.
In the examples below, we will revisit the examples in “Associated Entities without Variable Substitution” and show how Variable Substitution would better refine the retrieval of data.
Example 1:
Original SQL without Variable Substitution = Select * from M_B
New SQL with Variable Substitution = Select * from M_B where a_id IN ({ A.id })
PRIMARY_NAME = B
PARENT_ENTITY = A
PARENT_ROLENAME = toB
As in a previous example, here is the Data in the M_A and M_B Table.
Using the following SQL (which includes Variable Substitution):
Select * from M_B where A_ID IN ({ A.id })
This then gets updated to Select * from M_B where A_ID IN ( 1, 2, 3 )
The SQL retrieval will only retrieve eight rows because of the WHERE clause.
As noted before, the Variable Substitution should follow the Foreign Key relationship between the two Tables. In this case, M_A has a 1 -> Many relationship to M_B, where M_B.A_ID is a Foreign Key back to M_A.ID.
This Foreign Key relationship is expressed in the WHERE clause of A_ID IN ({ A.id }), which translates to M_B.A_ID = M_A.ID where ID is IN the set of ( 1, 2, 3 ).
The Vocabulary Association’s Join Expression would also be expressed as: M_B.A_ID = M_A.ID
The results from this example will be the same as the results from “Associated Entities without Variable Substitution” Example #2. However, with less rows retrieved, translating the Database data into Corticon working memory will be faster.
Example 2:
This example is more complicated because the Foreign Key relationship includes multiple Columns. But as described in the previous example, the SQL statement with Variable Substitution should represent what the Foreign Key relationship is between the two Database Tables.
Revisiting “Associated Entities without Variable Substitution” Example #3…
This Join Expression would translate to the following Where clause:
:: Where Q_THREE.ID = Q_FOUR.Q_THREE_ID AND Q_THREE.Q_ONE_ID = Q_FOUR.Q_ONE_ID AND Q_THREE.Q_TWO_ID = Q_FOUR.Q_TWO_ID
Now replace the Q_THREE values with Vocabulary Entity.Attribute information using an IN clause.
Final updated SQL statement:
Select * from Q_FOUR Where Q_FOUR.Q_THREE_ID IN ( {C_Three.id} ) AND Q_FOUR.Q_ONE_ID = ( {C_Three.one_id} ) AND Q_FOUR.Q_TWO_ID = ( {C_Three.two_id} )
SQL = Select * from Q_FOUR Where Q_FOUR.Q_THREE_ID IN ( {C_Three.id} ) AND Q_FOUR.Q_ONE_ID = ( {C_Three.one_id} ) AND Q_FOUR.Q_TWO_ID = ( {C_Three.two_id} ) PRIMARY_NAME = D_Four PARENT_ENTITY = C_Threes PARENT_ROLENAME = toD_Four
Using the following data inside Q_Three and Q_Four:
Those rows with Q_Four.ID = 5 through 10 will be filtered out by the WHERE clause, which reduces the ResultSet from the Database.
The results below are the same as in the Associated Entities without Variable Substitution Example #3.
Tips and Techniques
The following topics describe insights into techniques and behavior you might find useful.
When to use Comparison Operators instead an IN ( ) in the WHERE clause
It is highly recommended to use an IN ( ) clause instead of an = sign in your WHERE clause. In essence, they mean the same thing, yet, the IN ( ) clause can handle multiple values, while the = sign can only handle one value.
As outlined in the first example, there are three A Entities in memory. That means there are three values for { A.id }. In the following SQL note that the one with the IN ( ) is valid while the = sign is not:
Select * from M_A where id IN ( 1, 2, 3 ) Valid Select * from M_A where id = 1, 2, 3 Invalid
You cannot use an IN clause with <, <=, >, and =>. To prevent invalid SQL through Variable Substitution with <, <=, >, and =>, there can only be one instance of the Entity in working memory.
Inserting multiple rows into specific Database Table(s)
SCO Service Name = CcDatabaseServiceCallout.insertEntitiesIntoDatabase
The ADC will use the metadata inside the CCDATASOURCES, CCUPDATES, and CCINSERTS Tables to determine which Entities in the Vocabulary will be used to insert into which Database Table.
The core Table that contains which Entity or Entities will be inserted into the Database is in the CCINSERTS Table. This section describes how the SEQUENCE, SQL, PRIMARY_NAME are used in one or multiple CCINSERTS to insert multiple records into the intended Table.
Much like the CCREADS’ SEQUENCE field, the CCINSERTS’ SEQUENCE field determines in which order the CCINSERTS will fire. For each CCINSERTS’ SQL, there is a PRIMARY_ENTITY, which is used to create individual Insert Statements to be used by the Database.
Variable Substitution is used to substitute the PRIMARY_ENTITY values into the SQL Statement.
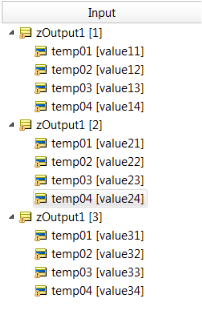
For every instance of zOutput1 in memory a new SQL Statement will get created using those values inside the zOutput1 instance.
With regards to the SQL statement, the user controls it, and can customize the SQL to match the Identity Strategy appropriate for a particular Database:
In Oracle, Database Sequences are used to set the Primary Keys. You need to create your own Database Sequence and add that Sequence Name to the SQL statement. In the above SQL, the first VALUE is zOutput1Sequence.nextval – the name of the Sequence that is used in this example.
In SQL Server, you can just set your Table to use Identity strategy to populate the Primary Key. In this case, the above SQL wouldn’t have a Column: ID and VALUE: zOutput1Sequence.nextval in it.
Also, because you have control over the SQL, you can inject Database specific Value/Functions directly in the SQL. In this example, Column: TIMESTAMP is not related to Entity zOutput1. The value is determined by the sysdate function on Oracle.
Consider this data to be what is in working memory:
There are three zOutput1 Entity instances. Each one will use the SQL statement as a template to create their own INSERT statement.
Note: Technical note: These are actually Prepared Statements in Batch Mode, but the concept that each instance of zOutput1 gets its own SQL statements is easier to present here.
Entity/Attribute names do not need to match Database Table/Column names
This section describes the level of integration between the Vocabulary Entity/Attribute/Association and the Database Table/Columns.
CcRetrievals will retrieve data from the Database and incorporate that data into the working memory of the existing execution. The way the ADC translates the data into working memory is by using what has been entered in the Vocabulary for Table Name (for Entities), Column Name (for Attributes), and Join Expression (for Associations).
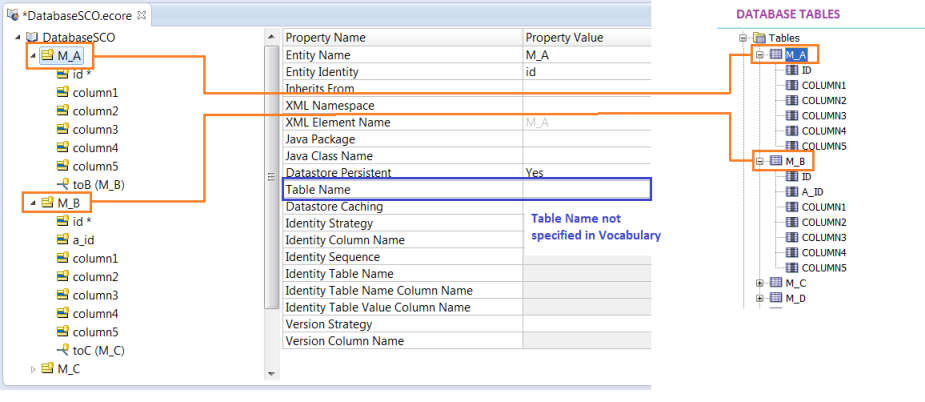
Entity -> Table Name (optional):
If this field is entered for the Entity, then it will be used by the ADC. If it is not entered, then the Entity Name will be used as the Table Name. It is only necessary to enter in a Table Name if the Vocabulary Entity Name does not match the Table Name in the Database.
Example 1: (Table Name not specified)
Example 2: (Table Name specified, Entity Name can be anything)
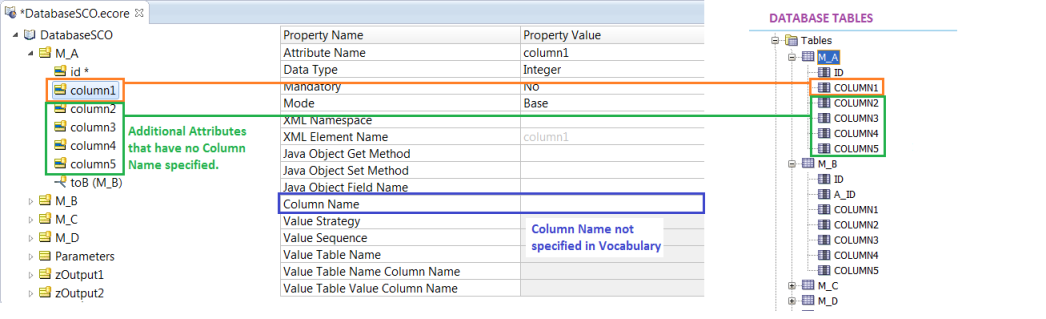
Attribute -> Column Name (optional)
This is similar to Entity -> Table Name. If the Column Name field is not entered, then the Attribute Name will be used for the Column Name.
Example 1: (Column Name not specified)
Example 2: (Column Name specified, Attribute Name can be anything)
Association -> Join Expression (required):
Join Expressions are required because there is no way to determine what the Foreign Key relationships are. If Database Metadata has been imported into the Vocabulary and the Vocabulary is able to decipher the Foreign Keys based on the Metadata, then the Join Expression doesn’t need to be manually entered.
If the Join Expression needs to be manually added, the Schema name will need to precede the Table name. In this example, DATASYNC is the Schema name.
Multiple ADC instances can be added to one or many Ruleflows
There is no restriction on how many ADC instances you can have in your Ruleflow. Its positiob on the Ruleflow canvas is based on your Use Case. When retrieving extra data is only needed in certain cases, you can put an ADC instance inside a Branch that will only fire under certain conditions. This can also applied to CCUPDATES.
Example:
In this example, there are two ADC instances in the main Ruleflow. The CcRetrievals SCO is embedded in another Ruleflow, 63-RetrieveABCD.erf, which is added to the main Ruleflow, 81-RetreiveABCD_UpdateBoth.erf, as:
These instances are highlighted in this illustration of the Main Ruleflow and the Embedded Ruleflow:
Each instance of the ADC works independently to do what it is assigned to do.
Each ADC task can use a different DataSource
Each instance of an ADC can call any CCRETRIEVALS or CCUPDATES operation, and for each CCRETRIEVALS and CCUPDATES, there is a CCDATASOURCES configuration. There is no restriction that all records in the CCDATASOURCES Table point to the same Database instance or even the same Database type.
Example:
Two records in CCDATASOURCES Table:
ID = 1, NAME=Corticon : This will be used by a CCRETRIEVALS to retrieve data from an Oracle Database.
ID = 2, NAME=Corticon (inserts) : This will be used by a CCUPDATES to insert data into a SQL Server Database.
Information when execution fails
Various errors can occur during the execution of the ADC. Some common issues are:
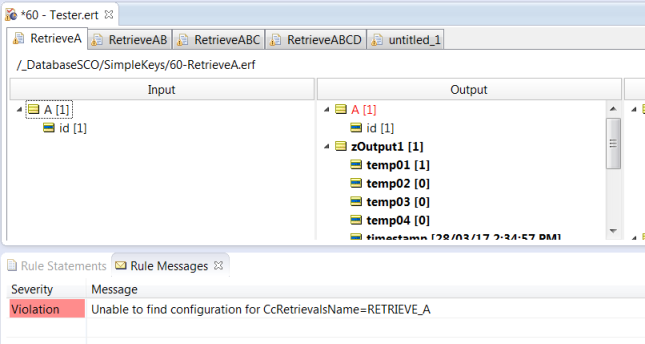
CcRetrievalsName or CcUpdatesName does not exist.
Bad SQL statement, possibly due to Variable Substitution issues.
Bad Join Statement definition for an Association.
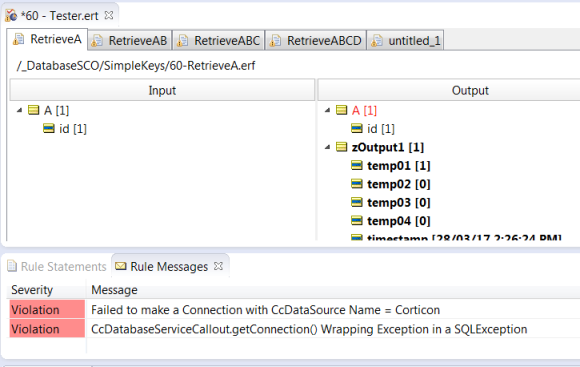
Failed to connect to the Database.
Whatever the type of error, execution will not only stop on the SCO, but for the entire execution. If there is an issue in the SCO, then current working memory could be incomplete or corrupted. Either way, the safest play is to stop all execution.
Also, there will an entry in the Corticon Log, with the Exception, and a CcRuleMessage -> Violation message added to the Response.
Example: (Database URL is bad)
Example: (Bad SQL Statement)
Example: (Bad CcRetrievalsName)
Scripts and examples
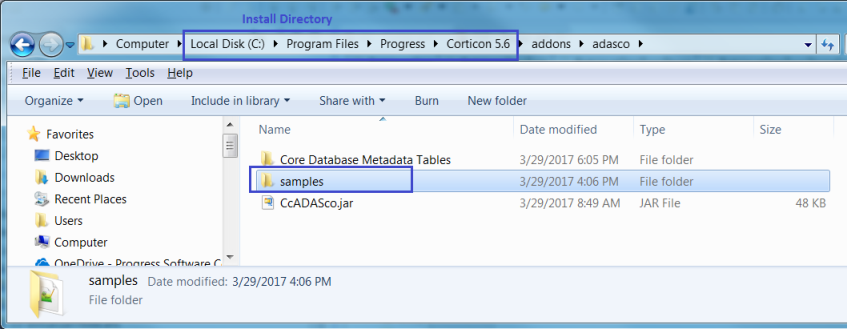
A Corticon installation provides scripts and examples located at [CORTICON_HOME]\addons\adasco.
Note: The JAR file at that location, CcADAsco.jar, must be added to your project. See Building the Java classes and JARs for instructions.
Installed Database Scripts that create required tables
Each type of Database can have subtle differences in their DDL (Data Definition Language). We are going to supply DDL Scripts (SQL Scripts) to create the necessary Tables in an Oracle Database. It is expected that a qualified DBA will be able to make the necessary alterations to the scripts so that they are compatible with their Database.
The only caveat about having the DBA alter the scripts would be, the names of the Tables and Columns must not be changed as these names are hardcoded to functionality in the ADC.
The SQL Scripts to generate the Oracle Database are distributed in Corticon Studio and Server Installers, as shown:
Rule Assets with Database Scripts to populate core Database Tables
The Rule Assets shown in the illustrations in this section are distributed in Corticon Studio and Server Installers, as shown:
Sample Simple Keys
Sample Simple Keys applies when the Database Tables only have one Column as a Primary Key. This makes Associations (through Join Expressions) similar to those using a multiple Columns as a Primary Key (which is covered in the ComplexKeys example). The sample provides database scripts and Corticon rule assets
Database Scripts for Sample Simple Keys
The order of running the Database Scripts is:
1. InsertsIntoCoreMetadataTables.txt - Inserts all the necessary Metadata into CCRETRIEVALS, CCREADS, CCUPDATES, and CCINSERTS Tables. A CCDATASOUCES record with ID=1 must already be in the Table; otherwise, the INSERT Statements will fail because they rely on a Foreign Key CCDATASOURCES_ID back to CCDATASOURCES with ID=1.
2. CreateTables.txt - Creates the core Tables that will be retrieved or inserted into the execution of the Decision Service.
3. DATA_M_A.csv, DATA_M_B.csv, DATA_M_C.csv, DATA_M_D.csv - The .csv files that you can import into the Table that were created with CreateTables.txt. NOTE: Import them in the order (A, B, C, D) as there are Foreign Key considerations.
RuleAssets for Sample Simple Keys:
DatabaseSCO.ecore - Vocabulary pre-configured with all the Database Mappings with Join Expressions for the Associations. The Database Mappings go hand in hand with the Database Scripts' CreateTables.txt.
Rulesheets - These are just for initialization of variables to make the example cleaner.
Ruleflows - A variety of Ruleflows that have ADC configured to run against different CcRetrievalsName and CcUpdatesName. These values go hand in hand with the data that was imported into the CCRETRIEVALS and CCUPDATES using the .csv files.
Ruletests - Several Ruletests, ## - Tester.ert, that demonstrate the various rule processing examples.
Sample Complex Keys
Sample Complex Keys is an example that applies when the Database Tables have cascading Primary Keys from one Table to another. Because Tables will have multiple Columns in the Primary Key, this complicates Associations and the corresponding Join Expressions.
As discussed in: “Associated Entities with no Variable Substitution”, Example 3, the Join Expression that links three Columns on each Entity together is:
ComplexKey.ecore - Vocabulary pre-configured with all the Database Mappings with Join Expressions for the Associations. The Database Mappings go hand in hand with the Database Scripts' CreateTables.txt.
Rulesheets - These are just for initialization of variables to make the example cleaner.
Ruleflows - A variety of Ruleflows that have ADC configured to run against different CcRetrievalsName and CcUpdatesName. These values go hand in hand with the data that was imported into the CCRETRIEVALS and CCUPDATES using the .csv files.
Tester.ert - A Ruletest that demonstrates the rule processing.