Our next step is to transform the diagram into our actual Vocabulary. This can be done directly in Corticon Studio using the built-in Vocabulary Editor feature.
Refer to the "Vocabulary" chapter of the Quick Reference Guide for complete details on building a Vocabulary inside Studio.
The following considerations apply to this transformation process:
The same naming conventions for entities and attributes used in the Fact Model will also be used in the Vocabulary.
All attributes in our Vocabulary must have a data type specified. These may be any of the following common data types: String, Boolean, DateTime, Date, Time, Integer or Decimal.
Attributes are classified according to the method by which their values are assigned. They are either:
Base -- Values are obtained directly from input data or request message, or
Transient -- Created, derived, or assigned by rules in Studio.
Transient attributes carry or hold values while rules are executing within a single Rulesheet. Since XML messages returned by a Decision Service do not contain transient attributes, these attributes and their values cannot be used by external components or applications. If an attribute value is used by an external application or component, it must be a base attribute.
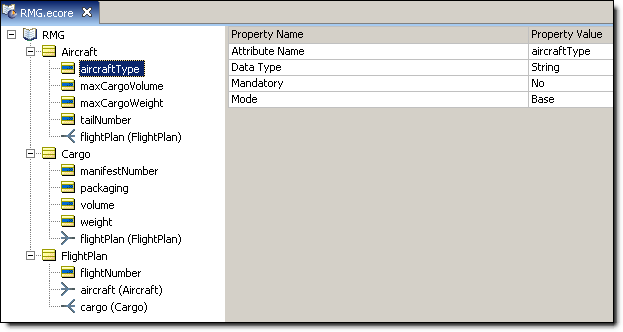
To show the rule modeler which attributes are base and which are transient, Corticon Studio adds an orange bar to transient attributes, as shown here for packDate:
XML response messages created by Corticon Server will not contain the packDate attribute.
It is a good idea to use a naming convention that distinguishes transient attributes from base attributes. For example, you could start a transient attribute's name with t_ such as t_packDate. We caution against modifying the names of terms so that they are cryptic. The intent is to express them in a language accessible to business users, as well as developers.
Associations between entities have role names that are assigned when building the associations in the UML class diagram or Vocabulary Editor. Default role names simply duplicate the entity name with the first letter in lowercase. For example, the association between the Cargo and FlightPlan entities would have a role name of flightPlan as seen by the Cargo entity, and cargo as seen by the FlightPlan entity. Roles are useful in clarifying context in a rule – a topic covered in more detail within the Scope chapter.
Associations between entities can be directional (one-way) or bi-directional (two-way). If the association between FlightPlan and Aircraft were directional (with FlightPlan as the source entity and Aircraft as target), we would only be able to write rules that traverse fromFlightPlantoAircraft, but not the other way. This means that a rule may use the Vocabulary term flightPlan.aircraft.tailNumber but may not useaircraft.flightPlan.flightNumber. Bi-directional associations allow us to traverse the association in either direction, which clearly allows us more flexibility in writing rules. Therefore, it is strongly recommended that all associations be bi-directional whenever possible. New associations are bi-directional by default.
Associations also have cardinality, which indicates how many instances of a given entity may be associated with another entity. For example, in our air cargo scenario, each instance of FlightPlan will be associated with only one instance of Aircraft, so we can say that there is a one-to-one relationship between FlightPlan and Aircraft. The practice of specifying cardinality in the Vocabulary deviates from the UML Class modeling technique because the act of assigning cardinality can be viewed as defining a constraint-type rule. For example, a flightPlan schedules exactly one aircraft and one cargo shipment is a constraint-type business rule that can be implemented in a Corticon Studio as well as embedded in the associations within a Vocabulary. In practice, however, it may often be more convenient to embed these constraints in the Vocabulary, especially if they are unlikely to change in the future.
Another consideration when creating a Vocabulary is whether derived attributes must be saved (or persisted) external to Corticon Studio, for example, in a database. It is important to note that while the structure of your Vocabulary may closely match your data model (often persisted in a relational database), the Vocabulary is not required to include all of the database entities/tables or attributes/columns, especially if they will not be used for writing rules. Conversely, our Vocabulary may contain attributes that are used only as transient variables in rules and that do not correspond to fields in an external database.
Finally, the Vocabulary must contain all of the entities and attributes needed to build rules in Corticon Studio that reproduce the decision points of the business process being automated. This will most likely be an iterative process, with multiple Vocabulary changes being made as the rules are built, refined, and tested. It is very common to discover, while building rules, that the Vocabulary does not contain necessary terms. But the flexibility of Corticon Studio permits the rule developer to update or modify the Vocabulary immediately, without programming.
Figure 4. Vocabulary Window in Corticon Studio
Note: In this figure, Corticon Studio Vocabulary is hiding its details. When changed to show Vocabulary details, the list exposes properties related to mapping.